
我有一个图表(用户-[喜欢]-
为了提高cypher查询性能,我设置了dbms. page ecache.内存=100g和wrapper.java。附加=-Xmx32g,希望整个neo4j可以加载到meomory中。但是,当我执行最短路径查询时,CPU使用率为1625%而MEMORY使用率仅为5.7%,并且我没有看到cypher查询的性能改进。我是否在设置中缺少了一些东西?或者我可以设置一些东西来更快地运行查询?我已经阅读了开发人员手册中的Performance Tuning指南,但没有找到解决方案。
EDIT1:密码查询是计算喜欢这两个项目的唯一用户的数量。完整模式将是(品牌)-[:有]-
profile
MATCH p = allShortestPaths((p1:Brand {FID:'001'})-[*..4]-(p2:Brand {FID:'002'}))
with [r in RELS(p)|type(r)] as relationshipPath,
[n in nodes(p)|id(n)][2] as user, p1, p2
return p1.FID, p2.FID, count(distinct user);
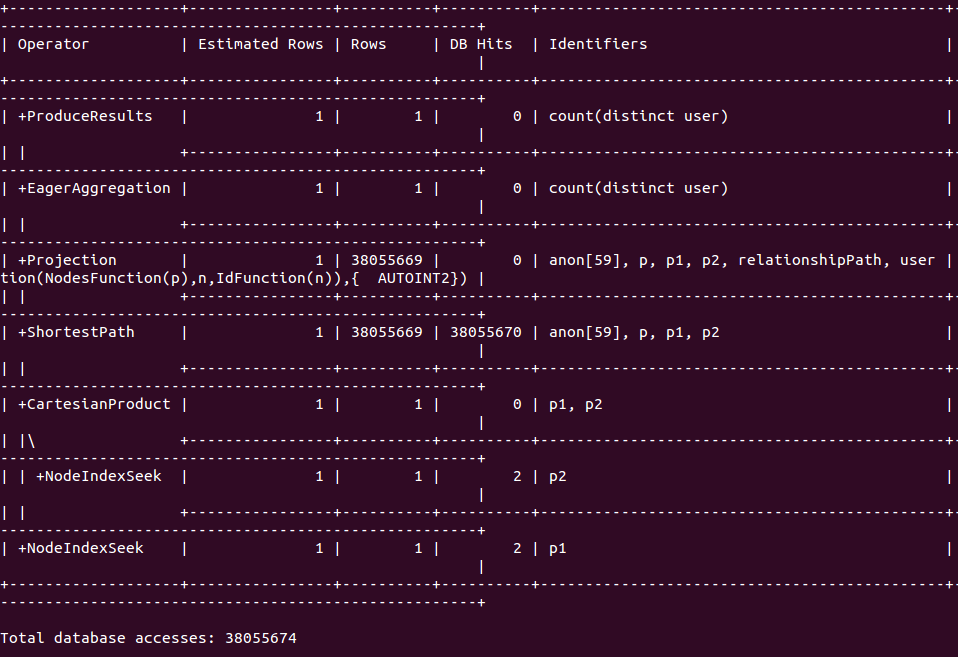
EDIT2:下面是一个采样器查询计划。现在看来我没有有效地使用短路径(380,556,69 db命中)。我使用短路径获取开始/结束节点之间的公共用户节点,然后使用count(不同)获取唯一用户。是否可以告诉cypher消除包含以前访问过的节点的路径?
你能试着运行这个吗:
MATCH (p1:Brand {FID:'001'}),(p2:Brand {FID:'002'})
MATCH (u:User)
WHERE (p1)-[:Has]->()<-[:LIKES]-(u) AND
(p2)-[:Has]->()<-[:LIKES]-(u)
RETURN p1,p2,count(u);
这从用户开始,并针对两个品牌进行检查,解释计划看起来要好得多
+----------------------+----------------+------------------------------------------+---------------------------+
| Operator | Estimated Rows | Variables | Other |
+----------------------+----------------+------------------------------------------+---------------------------+
| +ProduceResults | 0 | count(u), p1, p2 | p1, p2, count(u) |
| | +----------------+------------------------------------------+---------------------------+
| +EagerAggregation | 0 | count(u) -- p1, p2 | p1, p2 |
| | +----------------+------------------------------------------+---------------------------+
| +SemiApply | 0 | p2 -- p1, u | |
| |\ +----------------+------------------------------------------+---------------------------+
| | +Expand(Into) | 0 | anon[78] -- anon[87], anon[89], p1, u | (p1)-[:Has]->() |
| | | +----------------+------------------------------------------+---------------------------+
| | +Expand(All) | 0 | anon[87], anon[89] -- p1, u | (u)-[:LIKES]->() |
| | | +----------------+------------------------------------------+---------------------------+
| | +Argument | 1 | p1, u | |
| | +----------------+------------------------------------------+---------------------------+
| +SemiApply | 0 | p1 -- p2, u | |
| |\ +----------------+------------------------------------------+---------------------------+
| | +Expand(Into) | 0 | anon[119] -- anon[128], anon[130], p2, u | (p2)-[:Has]->() |
| | | +----------------+------------------------------------------+---------------------------+
| | +Expand(All) | 0 | anon[128], anon[130] -- p2, u | (u)-[:LIKES]->() |
| | | +----------------+------------------------------------------+---------------------------+
| | +Argument | 1 | p2, u | |
| | +----------------+------------------------------------------+---------------------------+
| +CartesianProduct | 0 | u -- p1, p2 | |
| |\ +----------------+------------------------------------------+---------------------------+
| | +CartesianProduct | 0 | p2 -- p1 | |
| | |\ +----------------+------------------------------------------+---------------------------+
| | | +Filter | 0 | p1 | p1.FID == { AUTOSTRING0} |
| | | | +----------------+------------------------------------------+---------------------------+
| | | +NodeByLabelScan | 0 | p1 | :Brand |
| | | +----------------+------------------------------------------+---------------------------+
| | +Filter | 0 | p2 | p2.FID == { AUTOSTRING1} |
| | | +----------------+------------------------------------------+---------------------------+
| | +NodeByLabelScan | 0 | p2 | :Brand |
| | +----------------+------------------------------------------+---------------------------+
| +NodeByLabelScan | 0 | u | :User |
+----------------------+----------------+------------------------------------------+---------------------------+
