我试图更深入地了解编程语言的低级操作是如何工作的,尤其是它们是如何与OS/CPU交互的。我可能已经阅读了堆栈上每个堆栈/堆相关线程中的每个答案
在伪代码中考虑这个函数,它往往是有效的Rust代码;-)
fn foo() {
let a = 1;
let b = 2;
let c = 3;
let d = 4;
// line X
doSomething(a, b);
doAnotherThing(c, d);
}
这就是我假设堆栈在X行上的样子:
Stack
a +-------------+
| 1 |
b +-------------+
| 2 |
c +-------------+
| 3 |
d +-------------+
| 4 |
+-------------+
现在,我读到的关于堆栈如何工作的所有内容都是,它严格遵守LIFO规则(后进先出)。就像堆栈数据类型一样。NET,Java或任何其他编程语言。
但是如果是这样的话,那么在第X行之后会发生什么呢?因为很明显,我们需要的下一件事是使用a和b,但是这意味着OS/CPU(?)必须首先弹出d和c才能回到a和b。但是接下来它会搬起石头砸自己的脚,因为它需要c和d在下一行。
所以,我想知道幕后到底发生了什么?
另一个相关问题。考虑我们传递对其他函数之一的引用,如下所示:
fn foo() {
let a = 1;
let b = 2;
let c = 3;
let d = 4;
// line X
doSomething(&a, &b);
doAnotherThing(c, d);
}
从我的理解来看,这意味着do东西中的参数本质上指向相同的内存地址,如foo中的a和b。但这又意味着在我们到达a和b之前不会弹出堆栈。
这两种情况让我认为我还没有完全掌握堆栈是如何工作的,以及它是如何严格遵循LIFO规则的。
调用栈也可以称为帧栈。
在LIFO原则之后堆叠的不是局部变量,而是被调用函数的整个堆栈帧(“调用”)。局部变量分别与所谓的函数序言和尾声中的那些帧一起推送和弹出。
在帧内,变量的顺序是完全不确定的;编译器适当地“重新排序”帧内局部变量的位置,以优化它们的对齐,以便处理器能够尽快获取它们。关键的事实是,变量相对于某个固定地址的偏移量在帧的整个生命周期内是恒定的——因此,取一个锚地址就足够了,例如,帧本身的地址,并使用该地址对变量的偏移量。这样的锚地址实际上包含在存储在EBP寄存器中的所谓的基或帧指针中。另一方面,偏移量在编译时是清楚的,因此被硬编码到机器代码中。
维基百科的这张图显示了典型的调用堆栈的结构,如1:
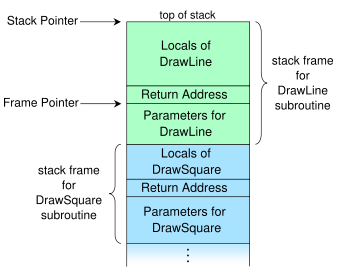
将我们想要访问的变量的偏移量添加到帧指针中包含的地址,我们就得到了我们变量的地址。所以简单地说,代码只是通过基指针的常量编译时偏移量直接访问它们;这是简单的指针算术。
#include <iostream>
int main()
{
char c = std::cin.get();
std::cout << c;
}
gcc.godbolt.org给了我们
main:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp
movl std::cin, %edi
call std::basic_istream<char, std::char_traits<char> >::get()
movb %al, -1(%rbp)
movsbl -1(%rbp), %eax
movl %eax, %esi
movl std::cout, %edi
call [... the insertion operator for char, long thing... ]
movl $0, %eax
leave
ret
… formain。我将代码分为三个小节。函数序言由前三个操作组成:
然后将cin移动到EDI寄存器2并调用get;返回值在EAX中。
到目前为止还不错。现在有趣的事情发生了:
EAX的低阶字节,由8位寄存器AL指定,被取并存储在基指针之后的字节中:即-1(%rbp),基指针的偏移量为-1。这个字节是我们的变量c。偏移量为负,因为堆栈在x86上向下增长。下一个操作将c存储在EAX中:EAX被移动到ESI,cout被移动到EDI然后使用cout和c作为参数调用插入运算符。
最后,
main的返回值存储在EAX: 0中。这是因为隐式的back语句。您可能还会看到xorl rax rax而不是movl。离开是这个尾声的缩写,隐含地
执行此操作和ret后,框架已有效弹出,尽管调用者仍然必须清理参数,因为我们使用cdecl调用约定。其他约定,例如stdcall,需要被调用者整理,例如通过将字节量传递给ret。
也可以不使用基/帧指针的偏移量,而是使用堆栈指针(ESB)的偏移量。这使得原本包含帧指针值的EBP寄存器可供任意使用——但它可能会使某些机器上的调试变得不可能,并且对于某些函数将被隐式关闭。当为只有少数寄存器的处理器编译时,包括x86,它特别有用。
这种优化被称为FPO(帧指针省略),由GCC中的-fomit-frame-poster和Clang中的-Oy设置;请注意,它是由每个优化级别隐式触发的
1正如注释中指出的,帧指针大概是指指向返回地址之后的地址。
2请注意,以R开头的寄存器是以E开头的寄存器的64位对应物。EAX指定RAX的四个低阶字节。为了清楚起见,我使用了32位寄存器的名称。
因为很明显,我们需要的下一件事是处理a和b,但这意味着OS/CPU(?)必须先弹出d和c才能回到a和b。但是它会搬起石头砸自己的脚,因为它需要c和d在下一行。
不需要弹出参数。调用者foo传递给函数do和为中的局部变量都可以作为基指针的偏移量被引用。
所以,
规则是每个函数调用都会创建一个堆栈帧(最小值是要返回的地址)。因此,如果funA调用funB并且funB调用funC,则三个堆栈帧一个接一个地设置。当一个函数返回时,它的帧变得无效。行为良好的函数仅作用于自己的堆栈帧,不会侵入另一个堆栈帧。换句话说,POPing是对顶部的堆栈帧执行的(从函数返回时)。
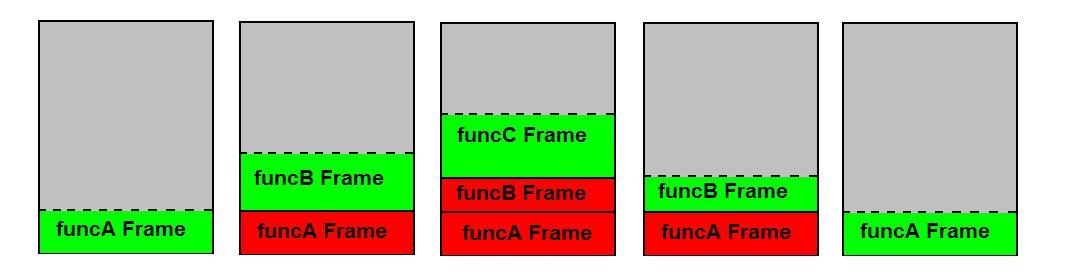
您问题中的堆栈是由调用者foo设置的。当do有东西和doAntherThing被调用时,它们会设置自己的堆栈。该图可能会帮助您理解这一点:
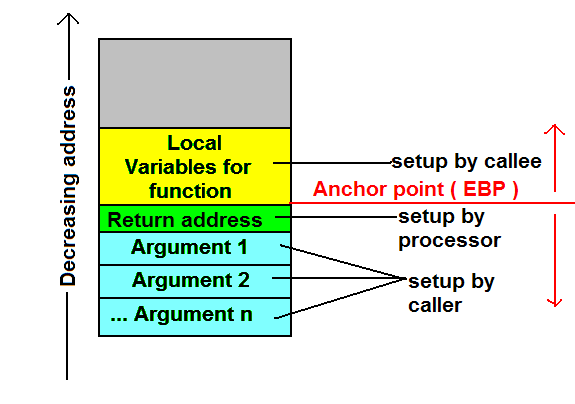
请注意,要访问参数,函数体必须从存储返回地址的位置向下遍历(较高地址),而要访问局部变量,函数体必须相对于存储返回地址的位置向上遍历堆栈(较低地址)。事实上,典型的编译器为函数生成的代码将完全做到这一点。编译器为此专门使用一个名为EBP的寄存器(Base Pointer)。另一个名称是帧指针。编译器通常作为函数体的第一件事,将当前EBP值推送到堆栈并将EBP设置为当前ESP。这意味着,一旦完成此操作,在函数代码的任何部分中,参数1距离EBP 8(调用者的EBP和返回地址各4个字节),参数2距离EBP 12(十进制),局部变量距离EBP-4n。
.
.
.
[ebp - 4] (1st local variable)
[ebp] (old ebp value)
[ebp + 4] (return address)
[ebp + 8] (1st argument)
[ebp + 12] (2nd argument)
[ebp + 16] (3rd function argument)
看看下面的C代码,用于形成函数的栈帧:
void MyFunction(int x, int y, int z)
{
int a, int b, int c;
...
}
当来电者打电话时
MyFunction(10, 5, 2);
将生成以下代码
^
| call _MyFunction ; Equivalent to:
| ; push eip + 2
| ; jmp _MyFunction
| push 2 ; Push first argument
| push 5 ; Push second argument
| push 10 ; Push third argument
并且函数的汇编代码将是(返回前由被调用者设置)
^
| _MyFunction:
| sub esp, 12 ; sizeof(a) + sizeof(b) + sizeof(c)
| ;x = [ebp + 8], y = [ebp + 12], z = [ebp + 16]
| ;a = [ebp - 4] = [esp + 8], b = [ebp - 8] = [esp + 4], c = [ebp - 12] = [esp]
| mov ebp, esp
| push ebp
参考资料:
就像其他人指出的那样,没有必要弹出参数,直到它们超出范围。
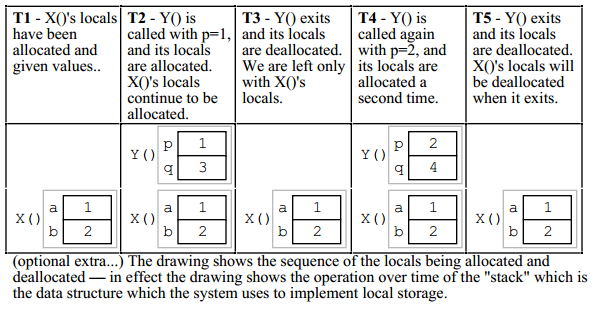
我会贴一些尼克·帕兰特的《指针与记忆》中的例子。我认为情况比你想象的要简单一点。
这是代码:
void X()
{
int a = 1;
int b = 2;
// T1
Y(a);
// T3
Y(b);
// T5
}
void Y(int p)
{
int q;
q = p + 2;
// T2 (first time through), T4 (second time through)
}
时间点T1、T2等。在代码中标记,当时的内存状态如图所示: