
---------------
我正在尝试开发一个读取和写入CloudSQL的数据流管道,但我面临很多连接问题。
首先,没有原生模板/解决方案可以做到这一点,所以我使用的是社区开发的库——
这是我到目前为止所做的:
模板
import argparse
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions, SetupOptions
from beam_nuggets.io import relational_db
def main():
# get the cmd args
db_args, pipeline_args = get_args()
# Create the pipeline
options = PipelineOptions(pipeline_args)
options.view_as(SetupOptions).save_main_session = True
with beam.Pipeline(options=options) as p:
source_config = relational_db.SourceConfiguration(
drivername=db_args.drivername,
host=db_args.host,
port=db_args.port,
database=db_args.database,
username=db_args.username,
password=db_args.password,
)
data = p | "Reading records from db" >> relational_db.ReadFromDB(
source_config=source_config,
table_name=db_args.table
query='select name, num from months' # optional. When omitted, all table records are returned.
)
records | 'Writing to stdout' >> beam.Map(print)
def get_args():
parser = argparse.ArgumentParser()
# adding expected database args
parser.add_argument('--drivername', dest='drivername', default='mysql+pymysql')
parser.add_argument('--host', dest='host', default='cloudsql_instance_connection_name')
parser.add_argument('--port', type=int, dest='port', default=3307)
parser.add_argument('--database', dest='database', default='irmdb')
parser.add_argument('--username', dest='username', default='root')
parser.add_argument('--password', dest='password', default='****')
parser.add_argument('--table', dest='table', default="table_name")
parsed_db_args, pipeline_args = parser.parse_known_args()
return parsed_db_args, pipeline_args
if __name__ == '__main__':
main()
作业在Dataflow中正确创建,但它仍然加载而不显示任何日志:
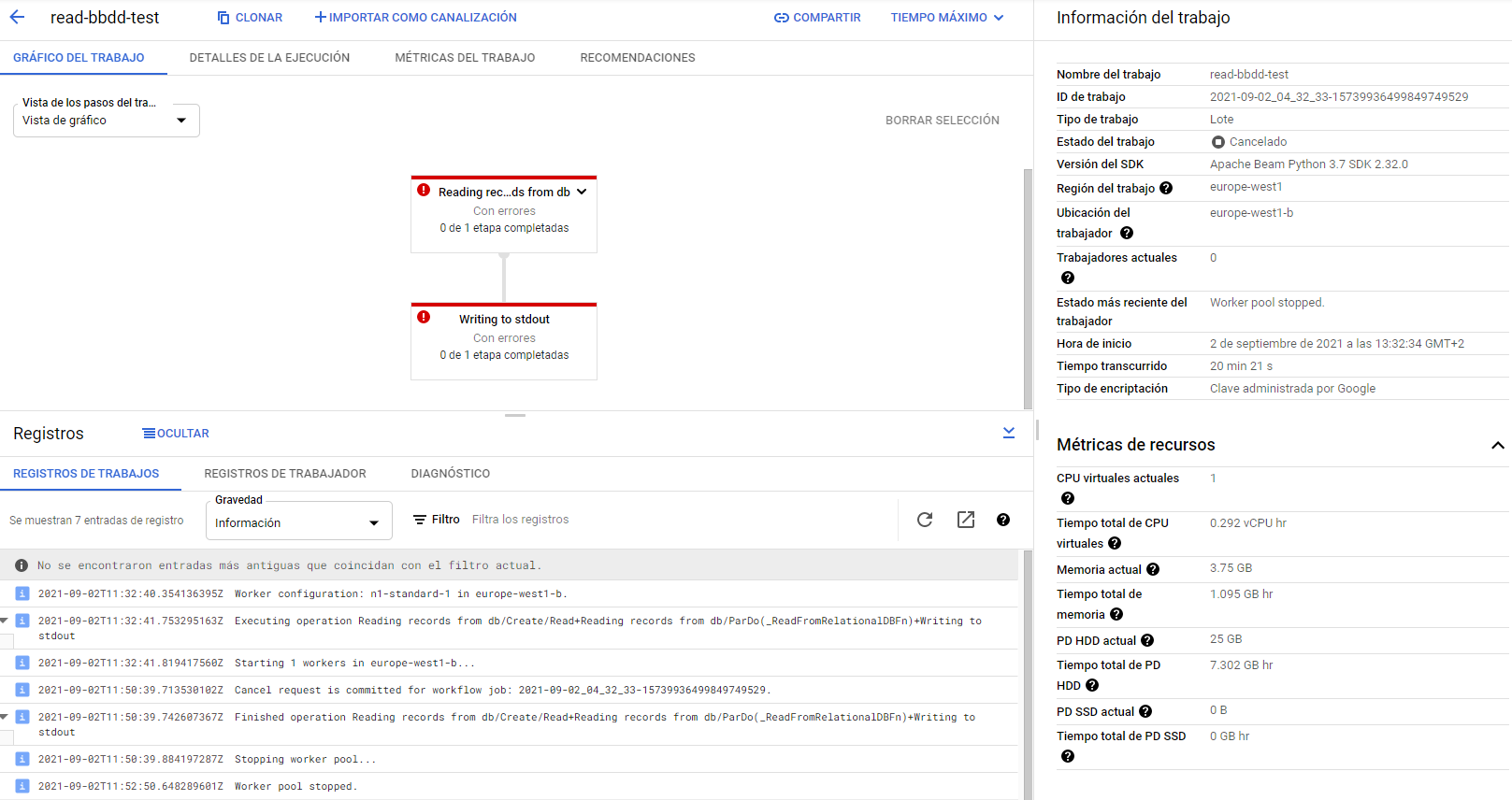
自从我停止工作后,它就显示为红色。
管道选项:

为什么我不能联系?我错过了什么?
提前感谢您的帮助。
-------------------
由于我没有得到任何关于beom-nugget库的结果,我已经切换到由Google创建的Cloud-sql-python连接器库。
让我们从头开始。
template.py
import argparse
from google.cloud.sql.connector import connector
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import SetupOptions
class ReadSQLTable(beam.DoFn):
"""
parDo class to get all table names of a given cloudSQL database.
It will return each table name.
"""
def __init__(self, hostaddr, host, username, password, dbname):
super(ReadSQLTable, self).__init__()
self.hostaddr = hostaddr
self.host = host
self.username = username
self.password = password
self.dbname = dbname
def process(self, element):
# Connect to database
conn = connector.connect(
self.hostaddr,
self.host,
user=self.username,
password=self.password,
db=self.dbname
)
# Execute a query
cursor = conn.cursor()
cursor.execute("SELECT * from table_name")
# Fetch the results
result = cursor.fetchall()
# Do something with the results
for row in result:
print(row)
def main(argv=None, save_main_session=True):
"""Main entry point; defines and runs the wordcount pipeline."""
parser = argparse.ArgumentParser()
parser.add_argument(
'--hostaddr',
dest='hostaddr',
default='project_name:region:instance_name',
help='Host Address')
parser.add_argument(
'--host',
dest='host',
default='pymysql',
help='Host')
parser.add_argument(
'--username',
dest='username',
default='root',
help='CloudSQL User')
parser.add_argument(
'--password',
dest='password',
default='password',
help='Host')
parser.add_argument(
'--dbname',
dest='dbname',
default='dbname',
help='Database name')
known_args, pipeline_args = parser.parse_known_args(argv)
# We use the save_main_session option because one or more DoFn's in this
# workflow rely on global context (e.g., a module imported at module level).
pipeline_options = PipelineOptions(pipeline_args)
pipeline_options.view_as(SetupOptions).save_main_session = save_main_session
with beam.Pipeline(options=pipeline_options) as p:
# Read the text file[pattern] into a PCollection.
# Create a dummy initiator PCollection with one element
init = p | 'Begin pipeline with initiator' >> beam.Create(['All tables initializer'])
tables = init | 'Get table names' >> beam.ParDo(ReadSQLTable(
host=known_args.host,
hostaddr=known_args.hostaddr,
dbname=known_args.dbname,
username=known_args.username,
password=known_args.password))
if __name__ == '__main__':
# logging.getLogger().setLevel(logging.INFO)
main()
在Apache Beam留档之后,我们应该上传一个需求. txt文件来获取必要的包。
要求. txt
cloud-sql-python-connector==0.4.0
之后,我们应该能够创建数据流模板。
python3 -m template --runner DataflowRunner /
--project project_name /
--staging_location gs://bucket_name/folder/staging /
--temp_location gs://bucket_name/folder/temp /
--template_location gs://bucket_name/folder//templates/template-df /
--region europe-west1 /
--requirements_file requirements.txt
但是当我尝试执行它时,会出现以下错误:
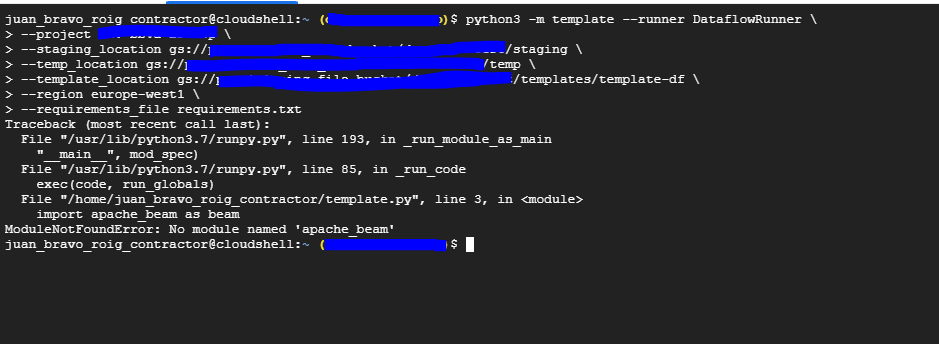
没有安装这些库… apache-光束和cloud d-sql-python-连接器都没有
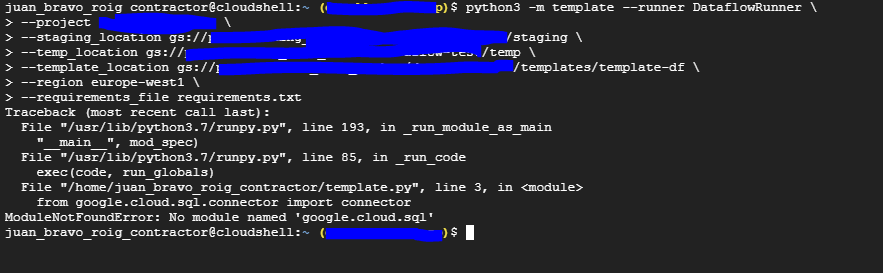
由于我在Cloud shell上遇到了这个错误,我尝试直接在shell上下载包(听起来很绝望,我是。)
pip3 install -r requirements.txt
pip3 install wheel
pip3 install 'apache-beam[gcp]'
我再次执行该函数。现在模板已经正确创建:

此外,我们应该创建一个template_metatada,其中包含有关参数的一些信息。我不知道我是否必须在这里添加其他内容,所以:
{
"description": "An example pipeline.",
"name": "Motor prueba",
"parameters": [
]
最后,我能够创建和执行管道,但与上次一样,它仍然在加载而不显示任何日志:
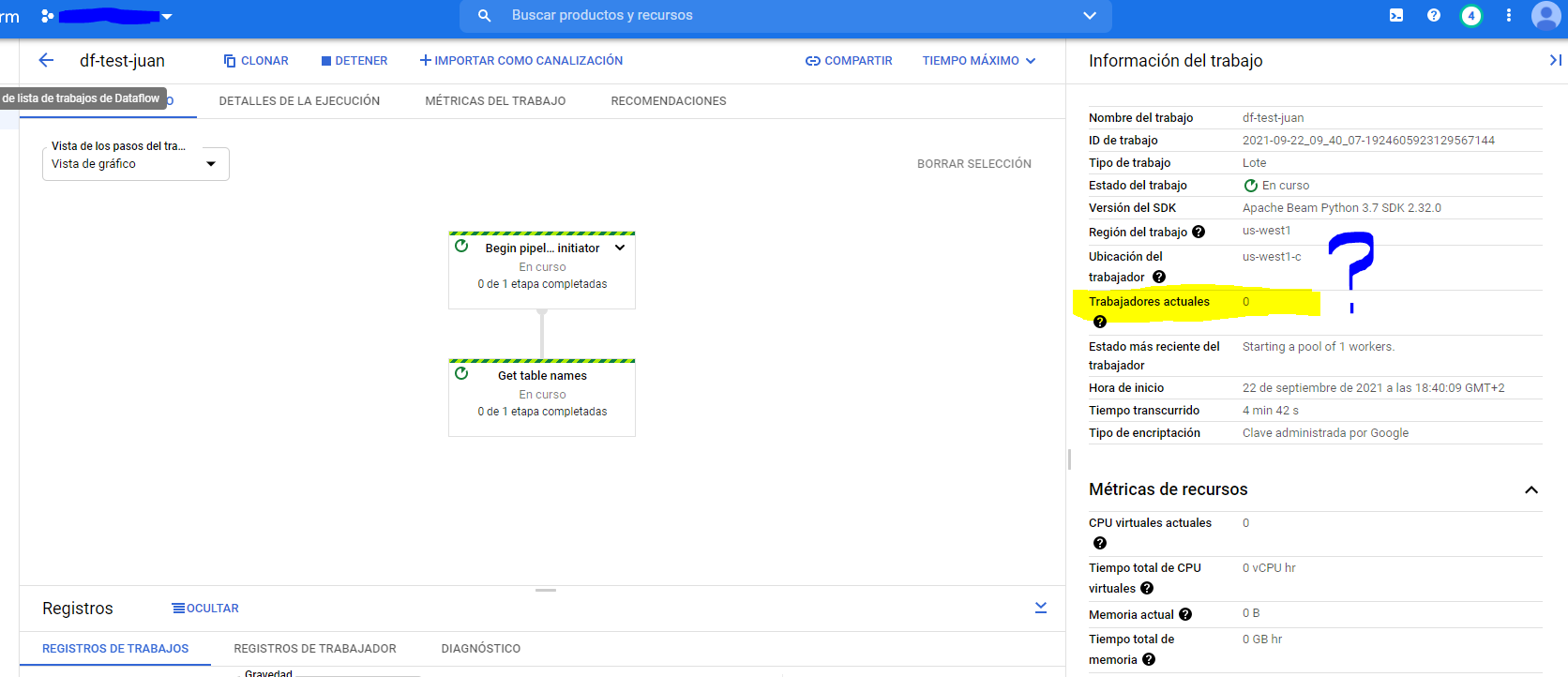
有线索吗?:/
我没有使用过nugget.io库,所以我不熟悉它如何处理连接。我建议尝试谷歌维护的Python连接器:
https://github.com/GoogleCloudPlatform/cloud-sql-python-connector
看看这是否能为你联系起来。
