
我有一个简单的管道,从PubSub接收数据,打印它,然后每隔10秒向GroupByKey发射一个窗口,并再次打印该消息。
然而,这个窗口有时似乎会延迟。这是谷歌的限制还是我的代码有问题:
with beam.Pipeline(options=pipeline_options) as pipe:
messages = (
pipe
| beam.io.ReadFromPubSub(subscription=known_args.input_subscription).with_output_types(bytes)
| 'decode' >> beam.Map(lambda x: x.decode('utf-8'))
| 'Ex' >> beam.ParDo(ExtractorAndPrinter())
| beam.WindowInto(window.FixedWindows(10), allowed_lateness=0, accumulation_mode=AccumulationMode.DISCARDING, trigger=AfterProcessingTime(10) )
| 'group' >> beam.GroupByKey()
| 'PRINTER' >> beam.ParDo(PrinterWorker()))
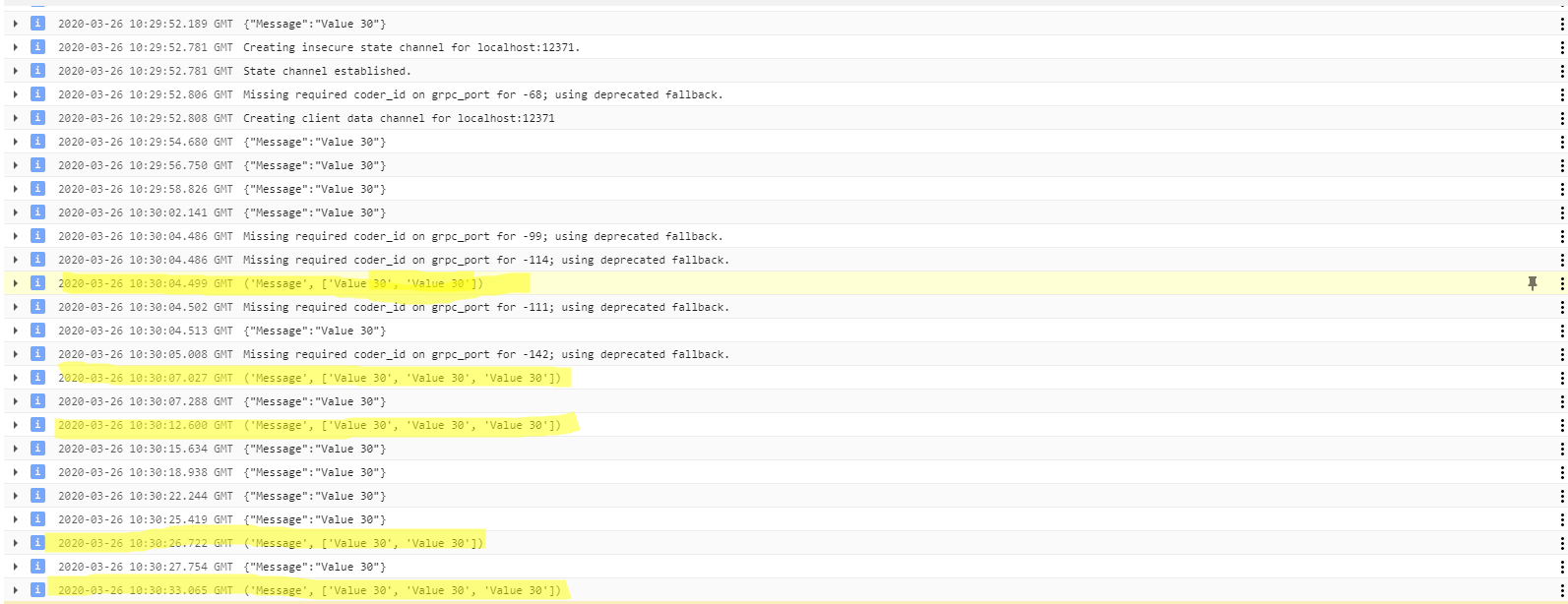
编辑最新代码。我删除了触发器,但问题仍然存在:
class ExtractorAndCounter(beam.DoFn):
def __init__(self):
beam.DoFn.__init__(self)
def process(self, element, *args, **kwargs):
import logging
logging.info(element)
return [("Message", json.loads(element)["Message"])]
class PrinterWorker(beam.DoFn):
def __init__(self):
beam.DoFn.__init__(self)
def process(self, element, *args, **kwargs):
import logging
logging.info(element)
return [str(element)]
class DefineTimestamp(beam.DoFn):
def process(self, element, *args, **kwargs):
from datetime import datetime
return [(str(datetime.now()), element)]
def run(argv=None, save_main_session=True):
"""Build and run the pipeline."""
parser = argparse.ArgumentParser()
parser.add_argument(
'--output_topic',
required=True,
help=(
'Output PubSub topic of the form '
'"projects/<PROJECT>/topics/<TOPIC>".'))
group = parser.add_mutually_exclusive_group(required=True)
group.add_argument(
'--input_topic',
help=(
'Input PubSub topic of the form '
'"projects/<PROJECT>/topics/<TOPIC>".'))
group.add_argument(
'--input_subscription',
help=(
'Input PubSub subscription of the form '
'"projects/<PROJECT>/subscriptions/<SUBSCRIPTION>."'))
known_args, pipeline_args = parser.parse_known_args(argv)
pipeline_options = PipelineOptions(pipeline_args)
pipeline_options.view_as(SetupOptions).save_main_session = save_main_session
pipeline_options.view_as(StandardOptions).streaming = True
with beam.Pipeline(options=pipeline_options) as pipe:
messages = (
pipe
| beam.io.ReadFromPubSub(subscription=known_args.input_subscription).with_output_types(bytes)
| 'decode' >> beam.Map(lambda x: x.decode('utf-8'))
| 'Ex' >> beam.ParDo(ExtractorAndCounter())
| beam.WindowInto(window.FixedWindows(10))
| 'group' >> beam.GroupByKey()
| 'PRINTER' >> beam.ParDo(PrinterWorker())
| 'encode' >> beam.Map(lambda x: x.encode('utf-8'))
| beam.io.WriteToPubSub(known_args.output_topic))
if __name__ == '__main__':
logging.getLogger().setLevel(logging.INFO)
run()
所以这基本上要求管道做的是将元素分组到10秒的窗口中,并在每个窗口接收到第一个元素后10秒后触发每个窗口(并丢弃该窗口的其余数据)。这是你的意图吗?
假设是这种情况,请注意,触发取决于系统接收到元素的时间以及每个窗口接收到第一个元素的时间。可能这就是您在结果中看到一些变化的原因。
我认为如果您需要对元素进行更一致的分组,您应该使用事件时间触发器而不是流转时长触发器。
所有触发器都基于最大努力意味着它们将在指定持续时间后的某个时间触发,在这种情况下为10秒。通常它发生在接近指定时间的地方,但可能会延迟几秒钟。
此外,还为关键窗口设置了触发器。窗口源自事件时间。10:30:04的第一GBK品脱可能是由于10:29:52的第一个元素。10:30:07的第二GBK打印是由于10:29:56的第一个元素
因此,最好打印每个元素的窗口和事件时间戳,然后共同关联数据。
