
为什么分支预测是准确的?我们是否可以从我们代码的某些分支是如何在99%的时间内执行的,而剩下的是特殊情况和异常处理的角度来普遍高估它?
我的问题有点模糊,但我只对这方面的高层观点感兴趣。让我给你一个例子
假设你有一个带参数的函数
void execute(Input param) {
assertNotEmpty(param)
(...)
}
我有条件地执行我的函数,给定参数不为空。99%的情况下,这个参数确实是非空的。然后,我能想到基于神经网络的分支预测吗?例如,在某种程度上,因为它已经见过无数次这样的指令流(这样的断言很常见),它会简单地学习大多数时候该参数是非空的,并相应地采取分支?
那么,我们是否可以从更干净、更可预测、甚至更常见的角度来考虑我们的代码——我们越容易将其用于分支预测器?
谢谢!
如何预测分支的简短历史:

没有预测,也没有预取,很快她开始在执行当前指令的同时预取下一条指令。大多数时候,这是正确的,在大多数情况下,每条指令的时钟提高了一个,否则不会丢失任何东西。这已经有了平均34%(59%-9%,H

有一个问题是,CPU的速度越来越快,并在管道中添加了解码阶段,使其获取-
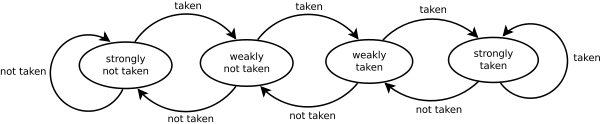

这一切都很好,但是一些分支取决于以前其他分支的行为。因此,如果我们有最后一个分支的历史记录,无论是否取为1和0,我们都有2^H不同的预测器,具体取决于历史记录。实际上,历史位与分支低地址位异或,使用与以前版本相同的数组。
PRO是预测器可以快速学习模式,CON是如果没有模式,分支将覆盖之前的分支位。PRO超过CON,因为局部性比不在当前(内部)循环中的分支更重要。这个全局预测器将错误预测降低到1%-11%。
这很好,但是在某些情况下,本地预测器击败了全局预测器,所以我们想要两者兼而有之。将本地分支历史与地址进行Xor处理可以提高本地分支预测,使其成为2级预测器,只是使用本地而不是全局分支历史。为每个计算正确的分支添加第三个饱和计数器,我们可以在它们之间进行选择。与全局预测器相比,此锦标赛预测器提高了约1%的错误预测率。
现在你的情况是另一个方向的100个分支中的一个。
让我们检查本地两级预测器,当我们到达一个案例时,该分支的最后H个分支都在同一个方向上,假设为已采取,使所有历史记录为1,因此分支预测器将在本地预测器表中选择一个条目,并且它将饱和以采取。这意味着它将在所有情况下对一个案例进行错误预测,并且下一次调用将采取的分支将很可能被正确预测(除非分支表条目出现混淆现象)。因此,本地分支预测器不能被使用,因为具有100位长的历史需要2^100的大预测器。
也许全局预测器捕获了这种情况,在最后99种情况下,分支被取走了,所以最后99种的预测器将根据最后H个分支移动它们以预测被取的不同行为进行更新。因此,如果最后H个分支具有与当前分支无关的行为,那么全局分支预测表中的所有条目都将预测被取,因此您将获得错误预测。
但是,如果先前分支的组合,例如第3、第7和第12分支,都采取了行动,如果采取/不采取正确的组合,则预示着相反的行为,此组合的分支预测条目将正确预测分支的行为。这里的问题是,如果您在程序运行时很少使用它们的行为更新此分支条目和其他分支别名,那么它可能无论如何都无法预测。
假设全局分支行为实际上基于先前分支的模式预测了正确的结果。然后你很可能会被锦标赛预测器误导,它说本地预测器“总是”正确的,而本地预测器总是错误地预测你的情况。
注1:“总是”应该用一小粒沙子来理解,因为其他分支可能会混淆现象污染你的分支表条目。设计者试图通过8K不同的条目来降低这种可能性,创造性地重新排列分支下部地址的位。
注2:其他方案可能能够解决这个问题,但不太可能,因为它是100分之一。
有几个原因使我们能够开发良好的分支预测器:
>
双模分布-分支的结果通常是双模分布的,即单个分支通常高度偏向已取或未取。如果大多数分支的分布是均匀的,那么就不可能设计出一个好的预测算法。
分支之间的依赖关系——在现实世界的程序中,不同分支之间存在大量依赖关系,即一个分支的结果会影响另一个分支的结果。例如:
if (var1 == 3) // b1
var1 = 0;
if (var2 == 3) // b2
var2 = 0;
if (var1 != var2) // b3
...
这里分支b3的结果取决于分支b1和b2的结果。如果b1和b2都被取消(即它们的条件评估为true并且var1和var2被分配为0),那么将采取分支b3。只查看单个分支的预测器没有办法捕获这种行为。检查这种分支间行为的算法称为两级预测器。
你没有要求任何特定的算法,所以我不会描述它们中的任何一个,但我会提到2位预测缓冲区方案,该方案工作得相当好,实现起来相当简单(本质上,人们跟踪缓存中特定分支的结果,并根据缓存中的当前状态做出决策)。该方案在MIPS R10000处理器中实现,结果显示预测准确率约为90%。
我不确定神经网络在分支预测中的应用——基于神经网络设计算法似乎是可能的。然而,我相信它不会有任何实际用途,因为: a)它在硬件中实现太复杂了(所以它需要太多的门并引入很多延迟);b)与更容易实现的传统算法相比,它不会对预测器的性能有显著提高。
许多语言提供了告诉编译器分支是最期望的结果的机制。它帮助编译器组织代码以最大化正分支预测。一个例子gcc__builtin_expect,可能,不太可能
