
我们正在构建相当复杂的数据流作业,其中计算来自流源的模型。特别是,我们有两个模型共享一堆指标,并且是根据大致相同的数据源计算的。这些作业在稍大的数据集上执行连接。
你对如何设计这种工作有什么指导方针吗?为了做出决策,我们需要考虑任何标准、行为或任何东西吗?
以下是我们想到的几个选项,以及我们如何比较它们:
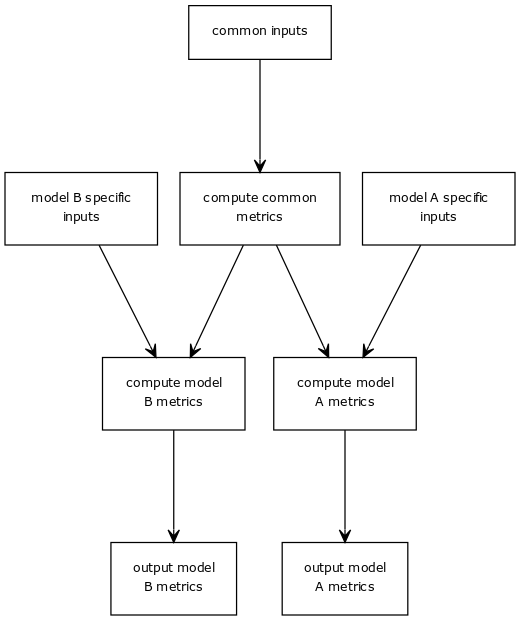
在一个大型作业中实现所有内容。考虑常见指标,然后计算特定于模型的指标。
将通用度量计算提取到一个专用作业中,从而生成3个作业,使用Pub/Sub连接在一起。
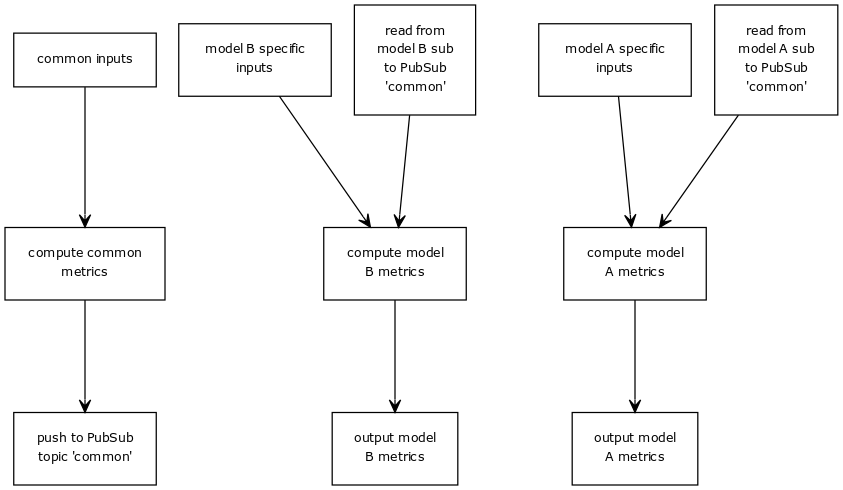
您已经在这里提到了许多关键的权衡——模块化和更小的故障域与操作开销以及单片系统的潜在复杂性。另一点需要注意的是成本——Pub/Sub流量将增加多管道解决方案的价格。
在不知道你的操作细节的情况下,我的建议是选择选项2。听起来有一个模型子集至少是有部分价值的,如果发生关键的bug或回归,你将能够在寻找修复的同时取得部分进展。
