
我有一个运行Beam/Dataflow作业的Python脚本
# add config
p = beam.Pipeline(options=pipeline_options)
# multiple dataflow processes . . .
# in some process I tryna raise the error to make dataflow job failed
result = p.run()
job_status = result.wait_until_finish()
if job_status == "FAILED":
# run something else
正如上面的代码,我试图处理Dataflow作业可能失败的情况,如果它失败了,将会有一个进程。但是在尝试了直接运行器和Dataflow运行器之后。作业结束于我在函数中提出的异常。但是对于如果作业成功的情况,它可以处理job_status函数,例如job_status=="DONE"
wait_until_finish()将返回管道的最终状态。所以,我想我可以使用这个函数来处理失败的作业,但它不起作用。有什么想法吗?
Dataflow控制台中显示的日志显示了我引发的异常及其结束,而没有在我的IF条件下运行任何内容
编辑:我的工作实际上是从一些网站上抓取数据并将其推送到GCS。失败的部分总是在抓取功能上,我不知何故通过网站获得403,我必须手动运行新的数据流作业来修复它。我只想用它来处理自动启动新工作。
def scrape_data():
# scrape data and return a json
def load_to_gcs():
# dump json to gcs
if __name__ == "__main__":
parser = argparse.ArgumentParser()
known_args, pipeline_args = parser.parse_known_args(sys.argv)
# Parse pipeline paramerters
pipeline_options = PipelineOptions(pipeline_args)
pipeline_options.view_as(SetupOptions).save_main_session = True
p = beam.Pipeline(options=pipeline_options)
id_list = ['aa','bb','cc'] # input param for scrape_data()
id = p | "init" >> beam.Create(id_list)
js = id | "scrape" >> beam.Map(scrape_data)
js | "load to gcs" >> beam.Map(load_to_gcs)
result = p.run()
job_status = result.wait_until_finish()
if job_status == "FAILED":
# run something else >> call dataflow api to start new job
当失败时(在抓取期间),数据流作业将自动重试4次,作业将失败。但是一旦失败,它就不会进入if条件。
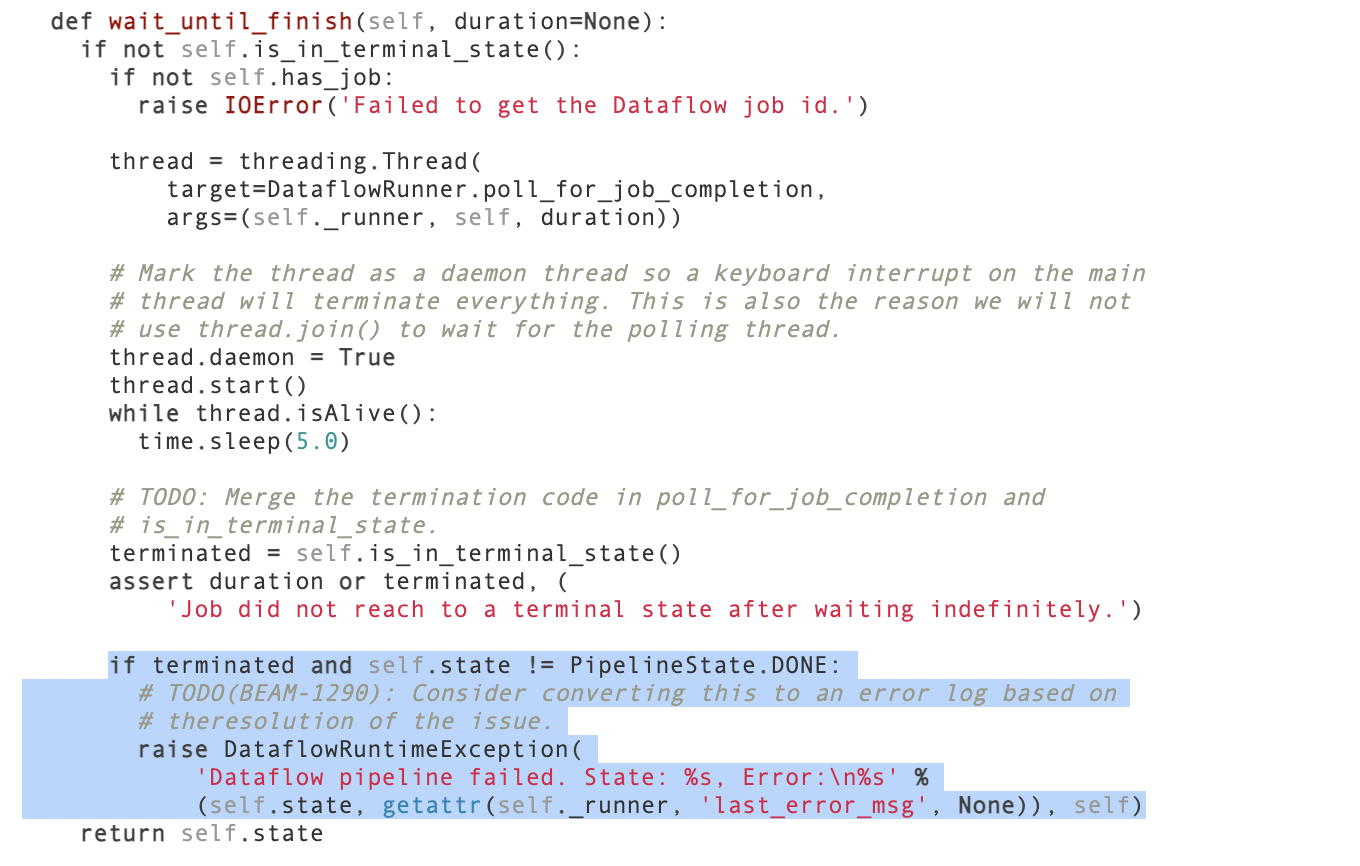
如果您的管道失败,DataflowRunner将抛出错误(请参阅此代码)。
您可能希望以这种方式处理:
try:
result.wait_until_finish()
except:
# Ignore the exception that may be thrown.
pass
finally:
if result.state == 'FAILED':
# Whatever you need to do about this
logging.error("Pipeline failed!")
这是一个合理的选择吗?
此问题已在此问题跟踪器中提出。我们目前无法提供ETA,但您可以在问题跟踪器中跟踪进度,并且可以通过参考此链接“STAR”问题以接收自动更新并给予关注。
