
我有一个1025个输入和14列的数据。首先,我通过将它们放在单独的表中来设置标签。
x = dataset.drop('label', axis=1)
y = dataset['label']
标签值仅为1或0。然后,我使用以下方法拆分数据:
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.30)
然后我做我的分类器:
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier()
classifier.fit(X_train, y_train)
然后每当我做我的决策树时,它就会变得太大:
from sklearn import tree
tree.plot_tree(classifier.fit(X_train, y_train))
结果输出了8个级别,但太大了。我认为这没问题,但在观察了混淆矩阵和分类报告后:
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
其结果是:
[[155 3]
[ 3 147]]
precision recall f1-score support
0 0.98 0.98 0.98 158
1 0.98 0.98 0.98 150
accuracy 0.98 308
macro avg 0.98 0.98 0.98 308
weighted avg 0.98 0.98 0.98 308
高精度让我怀疑我的解决方案。我的代码有什么问题,我如何降低决策树和准确性分数?
看起来你需要做的是检查以确保你的树没有过度安装。我们可以使用决策树和sklearn实现这一点,主要有两种方法。
首先,你应该检查一下,确保你的树是过度适合。您可以使用验证曲线(请参见此处)执行此操作。
验证曲线的示例如下所示:
import numpy as np
from sklearn.model_selection import validation_curve
from sklearn.datasets import load_iris
from sklearn.linear_model import Ridge
np.random.seed(0)
X, y = load_iris(return_X_y=True)
indices = np.arange(y.shape[0])
np.random.shuffle(indices)
X, y = X[indices], y[indices]
train_scores, valid_scores = validation_curve(Ridge(), X, y, "alpha",
np.logspace(-7, 3, 3),
cv=5)
train_scores
valid_scores
一旦你验证你的树是过度拟合的,你需要做一件叫做剪枝的事情,你可以使用@e-zeytinci提到的超参数优化来完成。您可以使用GridSearchCV来实现这一点。
GridSearchCV允许我们优化决策树或任何模型的超参数,以查看最大深度和最大节点(这似乎是OPs关注点),还可以帮助我们完成适当的修剪。
该实现的一个示例可以在这里阅读
下面是这篇文章中的一组工作代码示例:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
def dtree_grid_search(X,y,nfolds):
#create a dictionary of all values we want to test
param_grid = { 'criterion':['gini','entropy'],'max_depth': np.arange(3, 15)}
# decision tree model
dtree_model=DecisionTreeClassifier()
#use gridsearch to test all values
dtree_gscv = GridSearchCV(dtree_model, param_grid, cv=nfolds)
#fit model to data
dtree_gscv.fit(X, y)
return dtree_gscv.best_params_
或者,随机森林可以帮助决策树过拟合。
您可以实现一个RandomForestClassifier,并遵循上述相同的超参数调优。
这篇文章的一个例子如下:
from sklearn.grid_search import GridSearchCV
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
# Build a classification task using 3 informative features
X, y = make_classification(n_samples=1000,
n_features=10,
n_informative=3,
n_redundant=0,
n_repeated=0,
n_classes=2,
random_state=0,
shuffle=False)
rfc = RandomForestClassifier(n_jobs=-1,max_features= 'sqrt' ,n_estimators=50, oob_score = True)
param_grid = {
'n_estimators': [200, 700],
'max_features': ['auto', 'sqrt', 'log2']
}
CV_rfc = GridSearchCV(estimator=rfc, param_grid=param_grid, cv= 5)
CV_rfc.fit(X, y)
print CV_rfc.best_params_
如果您还包括您的培训和测试分数(您已经进行的测试),您可以验证您的决策树分数:
print(confusion_matrix(y_train, clf.predict(y_train))
print(classification_report(y_train, clf.predict(y_train))
如果你有类似的结果,你的树是很好的拟合,在准确性(精度)方面。您还可以检查此项是否有过盈/过盈。
对于过盈和欠盈的概念:
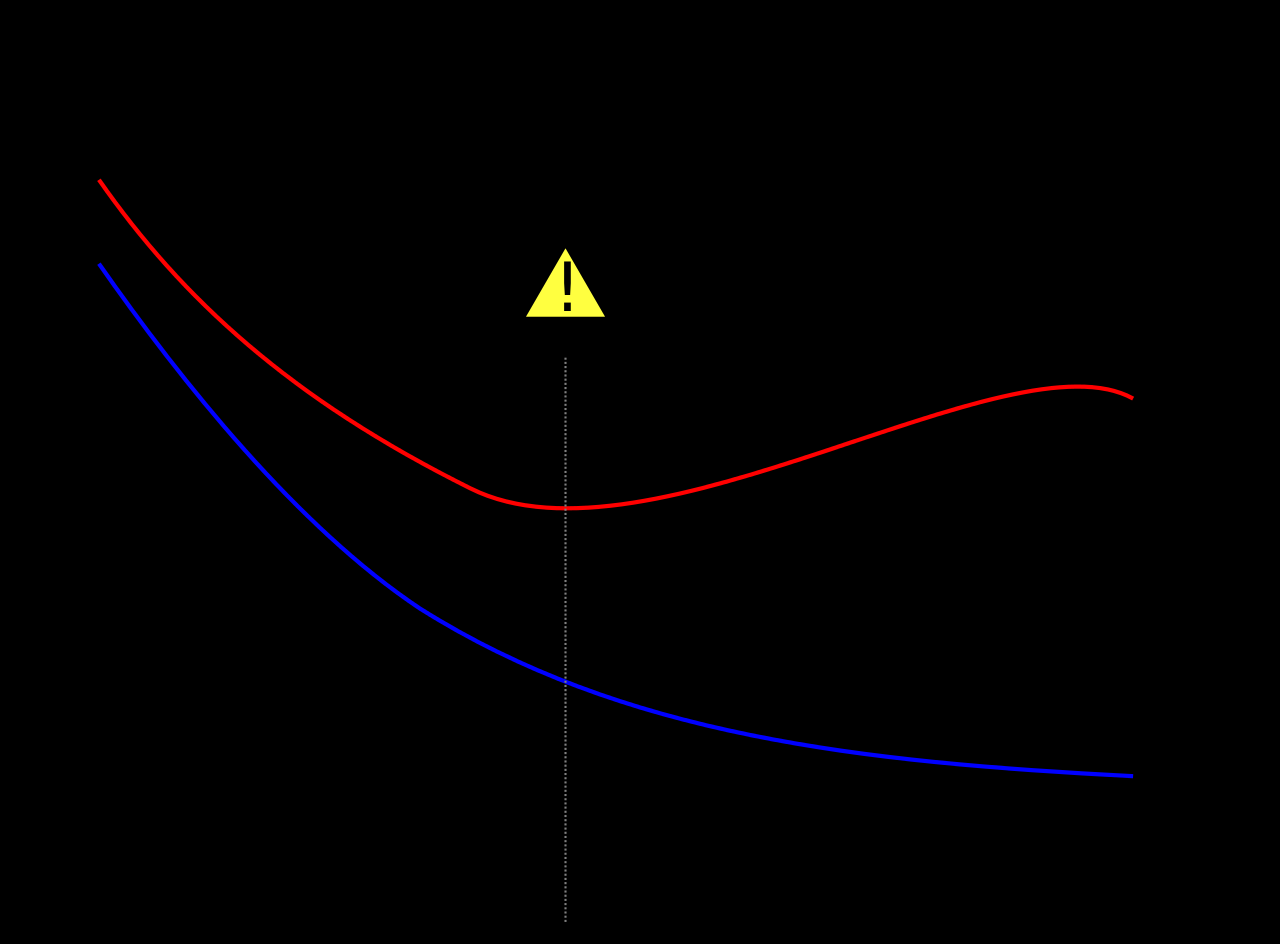
蓝色曲线是训练数据的误差,红色曲线是测试误差,在这里你可以看到蓝色误差下降,红色被卡住。这是过度拟合-这意味着训练数据对数据的影响很大。
但您的测试数据错误已经很低,这表明:
与最优函数相比,过度拟合的函数可能需要更多关于验证数据集中每个项目的信息;收集这些额外的不需要的数据可能代价高昂或容易出错,尤其是如果必须通过人工观察和手动数据输入来收集每一条信息。
始终提醒自己,只有14个标准可用。您可以在此处找到完整的参数:https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
如果你对平衡数据有如此准确的结果,我会问自己是否有一个特征(列)直接影响你的目标变量。关键词是数据泄露。这意味着你有一个特性,它只是因为你的目标变量而存在,在真正的测试中,你不会提前拥有它。得到一个想法的一个提示是:https://scikit-learn.org/stable/auto_examples/ensemble/plot_forest_importances.html
如果您仍然觉得您的树太深,可以使用以下方法调整最大深度:
classifier = DecisionTreeClassifier(max_depth= 4)
