
我们有一个Azure数据工厂(ADF)管道,其中第一个是数据库(DB)笔记本,用于轮询DB挂载的FS以获取新文件(通常是1天增量,基于“添加”的元数据字段)。然后,我们对该文件列表进行一些过滤,并将其传递给For每一个以开始实际的数据清理/插入管道。这对于每日增量更新来说效果很好,但是对于所有历史数据的完全摄取,我们会遇到来自数据工厂的错误。
我们通过dbutils. Notebook.Ex(file_list_dict)将第一个笔记本中过滤后的文件列表作为json传递,其中file_list_dict是一个Python字典,包含过滤后的路径作为json键下的数组,如下所示
{"file_list": [{"path": dbfs_filepath, "type": "File"}, ... ]
对于完整的摄取,ADF抛出一个错误,即json传递给DB笔记本不能超过20mb(因为它将包含数千个文件路径)并使管道失败。我尝试将json写入文件,并在该文件上进行For每操作符循环,但我找不到正确的方法。关于For每一个的留档只涉及管道活动中的项目,这在这里似乎是不可能的,因为我们所有的步骤本质上都是数据库笔记本。我还尝试从我写入FS的json文件中创建一个ADF数据集,并在查找活动中循环,但这也只支持5k行。
有没有一种简单的方法可以在我没有看到的文件行上进行For每一个循环?
管道示意图:
<DB file poll notebook & filter> -> <ForEach Operator for file in filelist> -> <run pipeline for individual files>
由于查找的限制为5000行,因此您可以尝试以下解决方法。
首先,尝试将文件列表作为JSON文件保存到数据库中大小为5000或以下的Blob存储文件夹中。
然后按照下面的演示:
我们可以使用MetaData和ForOne获得文件夹的JSON文件列表。要遍历每个JSON文件,我们需要另一个ForOne,但是不支持另一个ForOne中的ForOne。
但是,我们可以使用执行管道内的每个,我们可以在子管道中使用另一个每个。
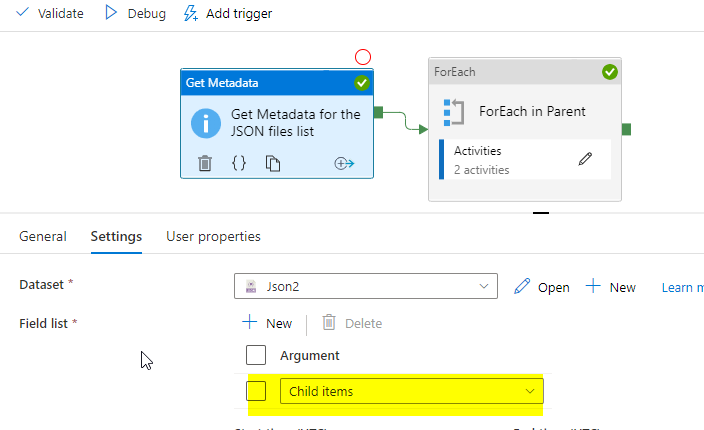
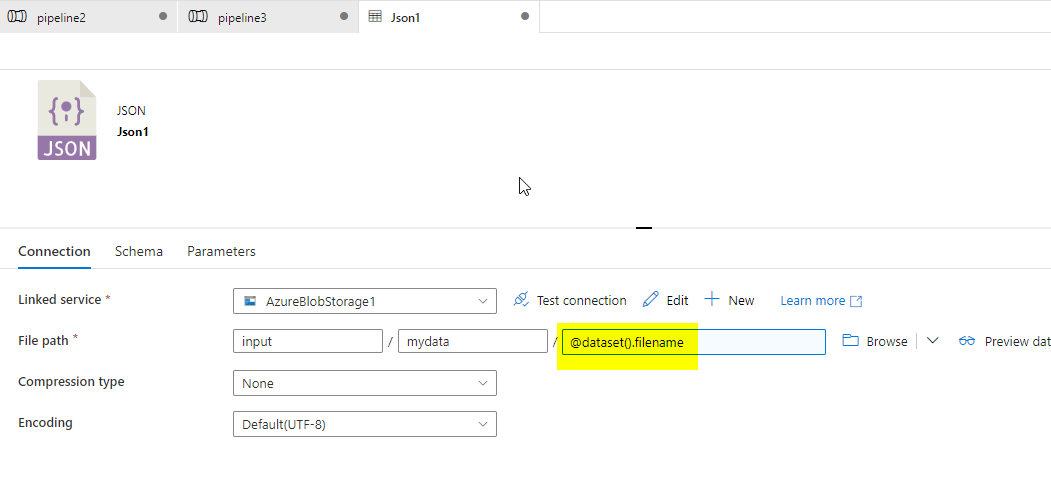
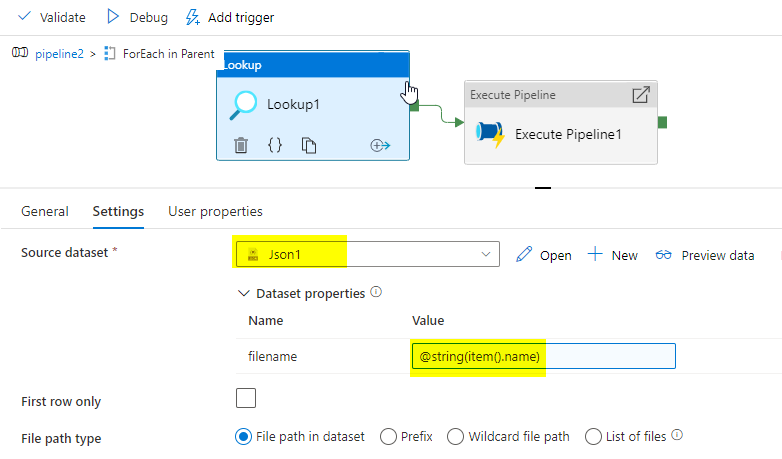
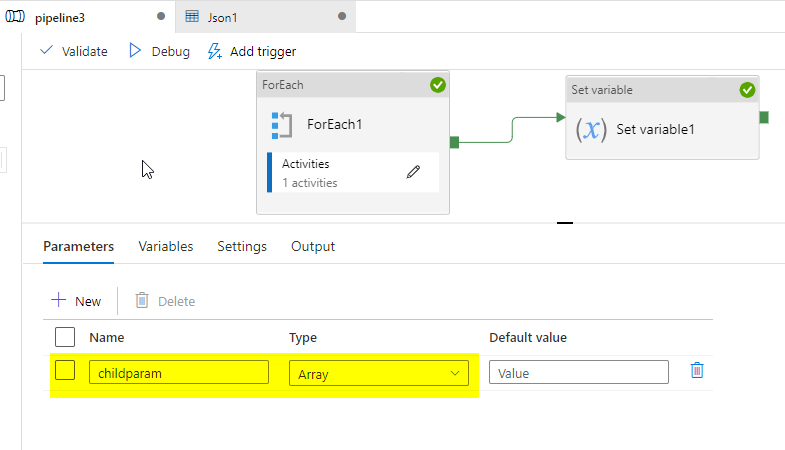
给出查找输出@active('Lookup1').输出. value
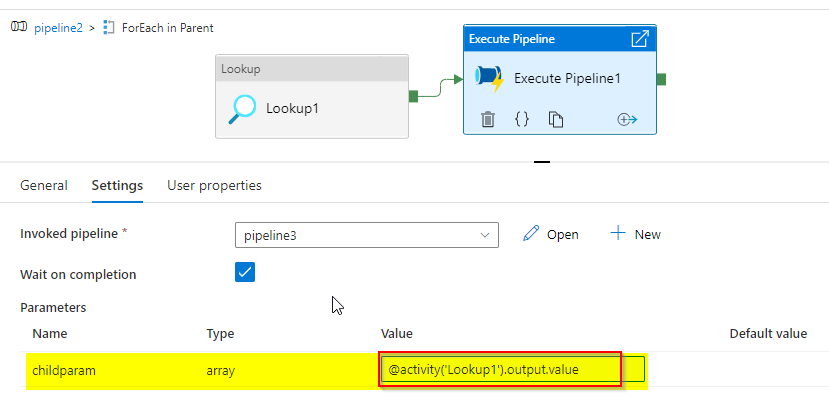
![]()
我们遇到了类似的问题(但是有点倒退,因为我们使用ADF轮询文件并将它们带入AzureSQLDB)。ADF和Database ricks之间的连接是通过API的,这就是限制所在。我们刚刚在ADF管道中执行了一个“直到”,并一次传递一组文件(基于输出json的大小)。
基本上直到没有更多的文件处理它们之类的事情。这是这个想法的截图。
[enter image description here][1]
[enter image description here][2]
[enter image description here][3]
[1]: https://i.stack.imgur.com/6RH5b.png
[2]: https://i.stack.imgur.com/pL6HN.png
[3]: https://i.stack.imgur.com/5Rf7s.png
