
我有一个regex101正确工作的regex:
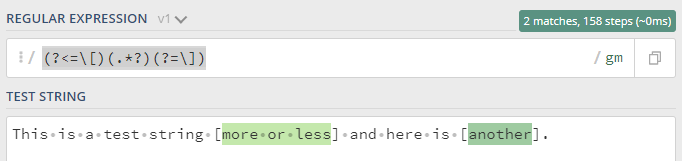
有2个匹配,如预期的。
现在我想用std的regex_token_iterator拆分相同的:
const std::string text = "This is a test string [more or less] and here is [another].";
const std::regex ws_re("\(?<=\[)(.*?)(?=\])\gm"); // HOW TO WRITE THE ABOVE REGEX IN HERE?
std::copy( std::sregex_token_iterator(text.begin(), text.end(), ws_re, -1),
std::sregex_token_iterator(),
std::ostream_iterator<std::string>(std::cout, "\n"));
这可以很好地编译,但没有任何东西被打印到stdout。
我认为正则表达式必须以其他方式编写,你能指出我的错误吗?
您可以使用
const std::regex ws_re(R"(\[([^\]\[]*)\])");
此外,确保通过将1作为最后一个参数传递给std::sregex_token_iterator而不是-1(拆分时使用-1)来提取组1值。
r“(\[([^\]\[]*)\])”是定义\[([^\]\[]*)\]正则表达式模式的原始字符串文本。匹配
\[-[字符([^\]\[]*)-组1:除[和]\]-]字符。请参阅C++演示:
#include <string>
#include <iostream>
#include <regex>
using namespace std;
int main() {
const std::string text = "This is a test string [more or less] and here is [another].";
const std::regex ws_re(R"(\[([^\]\[]*)\])");
std::copy( std::sregex_token_iterator(text.begin(), text.end(), ws_re, 1),
std::sregex_token_iterator(),
std::ostream_iterator<std::string>(std::cout, "\n"));
return 0;
}
