
这是我第一次使用谷歌的顶点AI管道。除了一些来自官方留档的链接之外,我还检查了这个codelab以及这篇文章和这篇文章。我决定把所有这些知识付诸实践,举个玩具例子:我计划构建一个由两个组件组成的管道:“get-data”(读取存储在云存储中的一些. csv文件)和“report-data”(基本上返回前一个组件中读取的.csv数据的形状)。此外,我很谨慎地包含了这个论坛中提供的一些建议。我目前拥有的代码如下:
from kfp.v2 import compiler
from kfp.v2.dsl import pipeline, component, Dataset, Input, Output
from google.cloud import aiplatform
# Components section
@component(
packages_to_install=[
"google-cloud-storage",
"pandas",
],
base_image="python:3.9",
output_component_file="get_data.yaml"
)
def get_data(
bucket: str,
url: str,
dataset: Output[Dataset],
):
import pandas as pd
from google.cloud import storage
storage_client = storage.Client("my-project")
bucket = storage_client.get_bucket(bucket)
blob = bucket.blob(url)
blob.download_to_filename('localdf.csv')
# path = "gs://my-bucket/program_grouping_data.zip"
df = pd.read_csv('localdf.csv', compression='zip')
df['new_skills'] = df['new_skills'].apply(ast.literal_eval)
df.to_csv(dataset.path + ".csv" , index=False, encoding='utf-8-sig')
@component(
packages_to_install=["pandas"],
base_image="python:3.9",
output_component_file="report_data.yaml"
)
def report_data(
inputd: Input[Dataset],
):
import pandas as pd
df = pd.read_csv(inputd.path)
return df.shape
# Pipeline section
@pipeline(
# Default pipeline root. You can override it when submitting the pipeline.
pipeline_root=PIPELINE_ROOT,
# A name for the pipeline.
name="my-pipeline",
)
def my_pipeline(
url: str = "test_vertex/pipeline_root/program_grouping_data.zip",
bucket: str = "my-bucket"
):
dataset_task = get_data(bucket, url)
dimensions = report_data(
dataset_task.output
)
# Compilation section
compiler.Compiler().compile(
pipeline_func=my_pipeline, package_path="pipeline_job.json"
)
# Running and submitting job
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
run1 = aiplatform.PipelineJob(
display_name="my-pipeline",
template_path="pipeline_job.json",
job_id="mlmd-pipeline-small-{0}".format(TIMESTAMP),
parameter_values={"url": "test_vertex/pipeline_root/program_grouping_data.zip", "bucket": "my-bucket"},
enable_caching=True,
)
run1.submit()
我很高兴看到管道编译没有错误,并设法提交了作业。然而,“我的快乐持续时间很短”,当我去顶点AI管道时,我偶然发现了一些“错误”,如下所示:
DAG失败,因为有些任务失败了。失败的任务有:[get-data]。; Job(project_id=my-project,job_id=4290278978419163136)由于上述错误而失败。;无法处理作业:{project_number=xxxxxxxx,job_id=4290278978419163136}
我在网上没有找到任何相关信息,也找不到任何日志或类似的东西,我感到有点不知所措,这个(看似)简单的例子的解决方案仍然在逃避我。
很明显,我不知道我弄错了什么或哪里。有什么建议吗?
根据评论中提供的一些建议,我想我设法使我的演示管道正常工作。我将首先包含更新的代码:
from kfp.v2 import compiler
from kfp.v2.dsl import pipeline, component, Dataset, Input, Output
from datetime import datetime
from google.cloud import aiplatform
from typing import NamedTuple
# Importing 'COMPONENTS' of the 'PIPELINE'
@component(
packages_to_install=[
"google-cloud-storage",
"pandas",
],
base_image="python:3.9",
output_component_file="get_data.yaml"
)
def get_data(
bucket: str,
url: str,
dataset: Output[Dataset],
):
"""Reads a csv file, from some location in Cloud Storage"""
import ast
import pandas as pd
from google.cloud import storage
# 'Pulling' demo .csv data from a know location in GCS
storage_client = storage.Client("my-project")
bucket = storage_client.get_bucket(bucket)
blob = bucket.blob(url)
blob.download_to_filename('localdf.csv')
# Reading the pulled demo .csv data
df = pd.read_csv('localdf.csv', compression='zip')
df['new_skills'] = df['new_skills'].apply(ast.literal_eval)
df.to_csv(dataset.path + ".csv" , index=False, encoding='utf-8-sig')
@component(
packages_to_install=["pandas"],
base_image="python:3.9",
output_component_file="report_data.yaml"
)
def report_data(
inputd: Input[Dataset],
) -> NamedTuple("output", [("rows", int), ("columns", int)]):
"""From a passed csv file existing in Cloud Storage, returns its dimensions"""
import pandas as pd
df = pd.read_csv(inputd.path+".csv")
return df.shape
# Building the 'PIPELINE'
@pipeline(
# i.e. in my case: PIPELINE_ROOT = 'gs://my-bucket/test_vertex/pipeline_root/'
# Can be overriden when submitting the pipeline
pipeline_root=PIPELINE_ROOT,
name="readcsv-pipeline", # Your own naming for the pipeline.
)
def my_pipeline(
url: str = "test_vertex/pipeline_root/program_grouping_data.zip",
bucket: str = "my-bucket"
):
dataset_task = get_data(bucket, url)
dimensions = report_data(
dataset_task.output
)
# Compiling the 'PIPELINE'
compiler.Compiler().compile(
pipeline_func=my_pipeline, package_path="pipeline_job.json"
)
# Running the 'PIPELINE'
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
run1 = aiplatform.PipelineJob(
display_name="my-pipeline",
template_path="pipeline_job.json",
job_id="mlmd-pipeline-small-{0}".format(TIMESTAMP),
parameter_values={
"url": "test_vertex/pipeline_root/program_grouping_data.zip",
"bucket": "my-bucket"
},
enable_caching=True,
)
# Submitting the 'PIPELINE'
run1.submit()
现在,我将添加一些补充意见,总而言之,这些意见设法解决了我的问题:
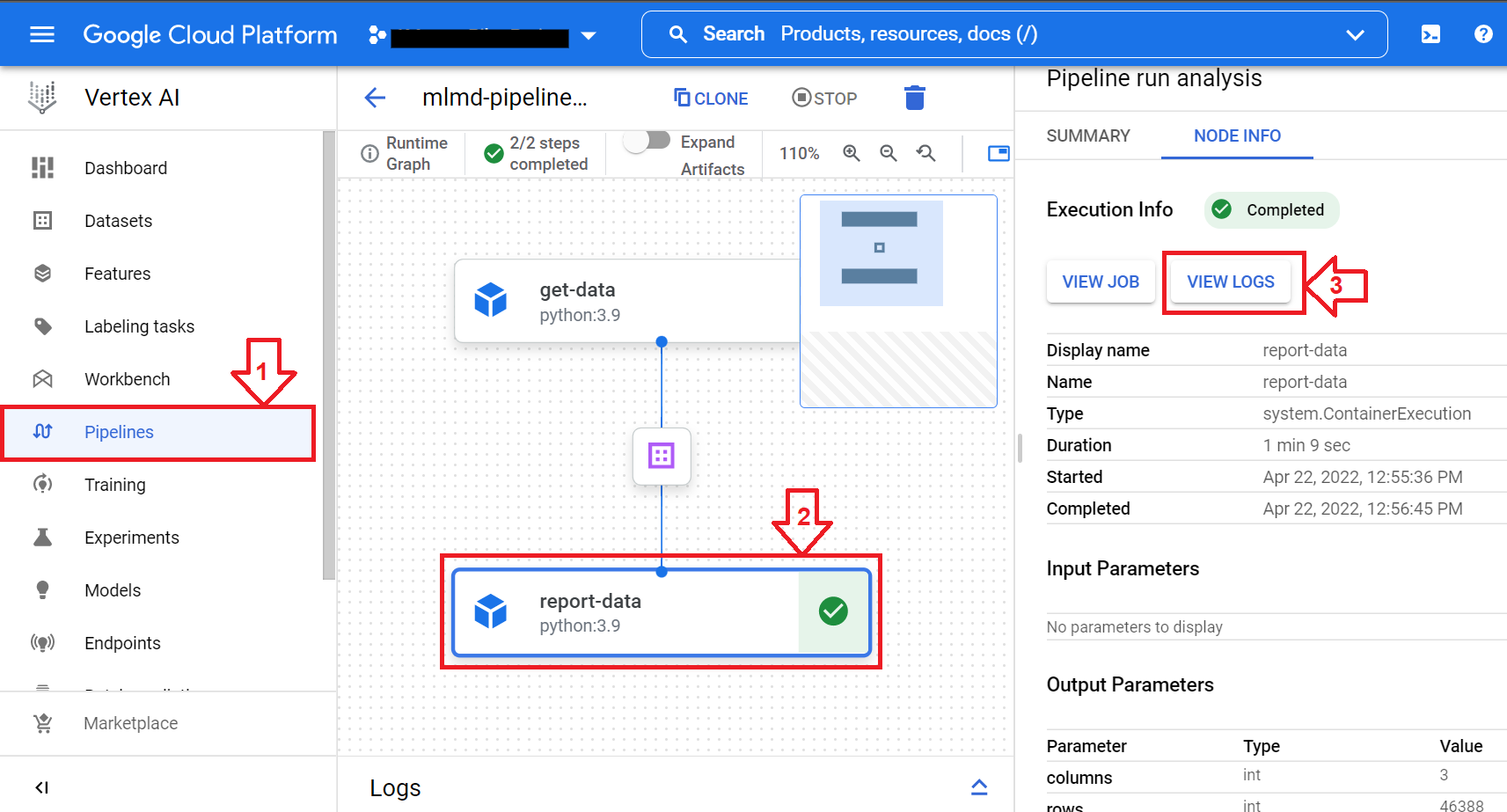
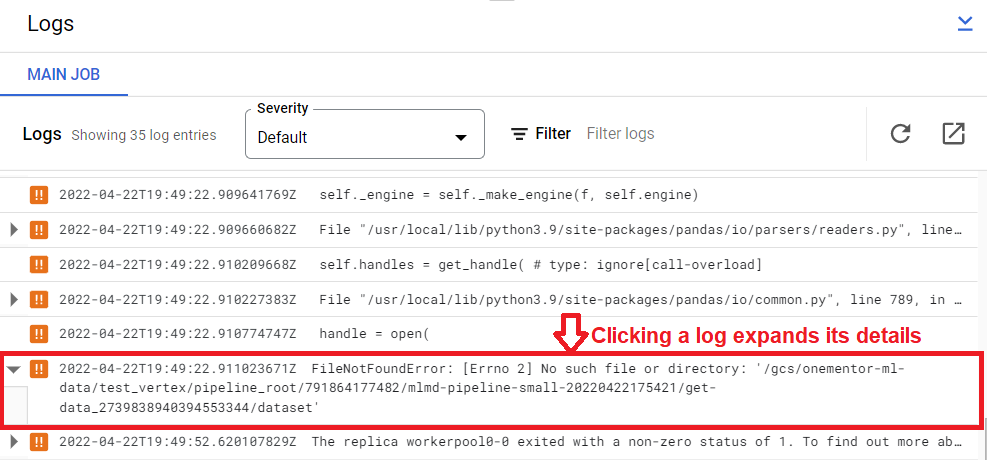
Input[Dataset]或Ouput[Dataset]时,需要添加文件扩展名(并且很容易忘记)。以get_data组件的输出为例,注意如何通过专门添加文件扩展名来记录数据,即dataset. path".csv"。当然,这是一个非常小的例子,项目可以很容易地扩展到大型项目,但是作为某种“你好顶点AI管道”,它会很好地工作。
谢谢你。
谢谢你的文章。非常有帮助!我有同样的错误,但结果是由于不同的原因,所以在这里注意到它…在我的管道定义步骤中,我有以下参数…
"'
def my_pipeline(bq_source_project: str = BQ_SOURCE_PROJECT,
bq_source_dataset: str = BQ_SOURCE_DATASET,
bq_source_table: str = BQ_SOURCE_TABLE,
output_data_path: str = "crime_data.csv"):
'''
我的错误是当我运行管道时,我没有输入这些相同的参数。下面是修复的版本…"'
job = pipeline_jobs.PipelineJob(
project=PROJECT_ID,
location=LOCATION,
display_name=PIPELINE_NAME,
job_id=JOB_ID,
template_path=FILENAME,
pipeline_root=PIPELINE_ROOT,
parameter_values={'bq_source_project': BQ_SOURCE_PROJECT,
'bq_source_dataset': BQ_SOURCE_DATASET,
'bq_source_table': BQ_SOURCE_TABLE}
'''
