
我对Hash和Rehash有些困惑。以下是我的理解,如果我错了,请纠正我。
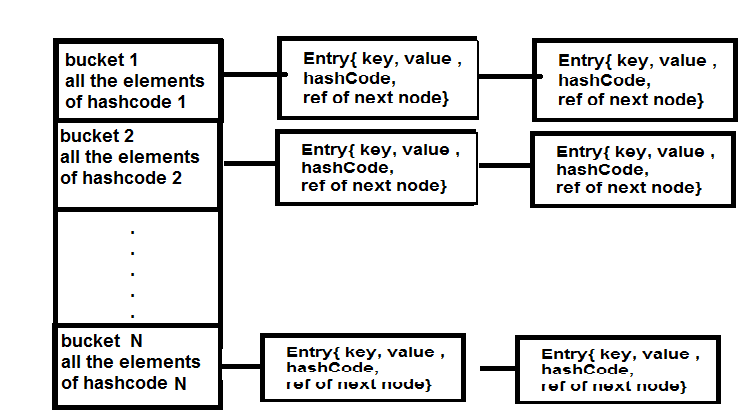
如图所示,bucket实际上是Entry类的数组,它以链表的形式存储元素。每个新的键值对,其键具有相同的入口数组存储桶的哈希码,将作为入口对象存储在存储该哈希码元素的存储桶中。如果键具有当前不存在于入口数组存储桶中的新哈希码,则将使用相应的哈希码添加一个新存储桶。
现在的问题是,什么时候真正发生了重新散列?
案例1:假设我有一个入口数组,其中包含一桶hashcode 1,2 3,在入口数组Bucket达到12时添加了新元素,它没问题,但是一旦一个新元素的hashcode是13(假设我添加了一系列hashcode 1然后2等元素),一个新的Map/Array of Entry Bucket(请澄清哪个)将被创建,新的容量将是32,现在Entry数组可以容纳不同的32个桶。
案例2:桶剂量物质的数量,HashMap 16的默认容量意味着它可以在其中存储16个元素,剂量物质在单个桶或任何情况下。
我认为情况2是正确的。请输入重新哈希过程,如果使用此图会更好。
重新散列会增加可用存储桶的数量,这是当前存储在HashMap中的条目数的函数。
当HashMap实现确定应该增加存储桶的数量以保持预期的O(1)查找和插入性能时,就会发生这种情况。
关于.75默认负载因子以及添加第13个条目时它将如何导致HashMap重新散列,您是正确的。
但是,HashMap 16的默认容量意味着它可以在其中存储16个元素是不正确的。任何存储桶都可以存储多个条目。但是,为了保持所需的性能,每个存储桶的平均条目数应该很小。这就是我们有负载因子的原因,也是我们应该使用适当的hashCode()将键尽可能均匀地分布在存储桶中的原因。
重新散列是重新计算已存储条目的hashcode(Key-Value对)的过程,以在达到负载因子阈值时将它们移动到另一个更大大小的hashmap。
当map中的项目数量超过负载因子限制时,hashmap的容量加倍,并且重新计算已存储元素的hashcode,以便在新桶中均匀分布键值对。
为什么需要重新散列?
容量翻倍后,如何处理桶中已经存在的键值对?
如果我们保持现有的键值对不变,那么将容量加倍可能无济于事,因为只有当项目均匀分布在所有桶中时,才能实现O(1)复杂度。
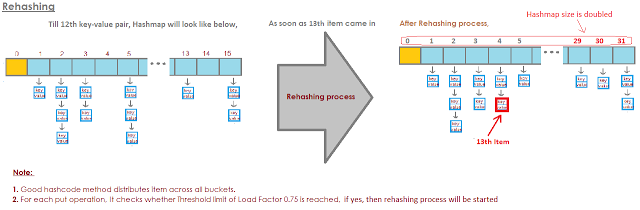
重新散列是为了在新的长度hashmap上分发项目,因此get和put操作时间复杂度保持O(1)。
注:
Hashmap在插入数据和从hashmap获取数据时保持O(1)的复杂性,但是对于第13个键值对,put request将不再是O(1),因为一旦map意识到第13个元素进来,即map的75%被填充。
它将首先将桶(数组)容量翻倍,然后将用于Rehash。重新散列需要重新计算已经放置的12个键值对的哈希码,并将它们放在需要时间的新索引中。
你应该读一下这个可能会有帮助
http://javabypatel.blogspot.co.il/2015/10/what-is-load-factor-and-rehashing-in-hashmap.html
