
我正在努力确保我清楚地了解我的组织如何为Google Cloud Platform Dataproc计费。
我们已经将账单历史导出到BigQuery,以便我们进行分析。今天早上,我们运行了两个dataproc集群,下面的屏幕截图显示了这两个集群的账单历史子集。我已经过滤了labels. key="goog-dataproc-grouster-uuid"或labels.key="goog-dataproc-grouster-name"或labels.key="goog-dataproc-place"。这是结果的子集
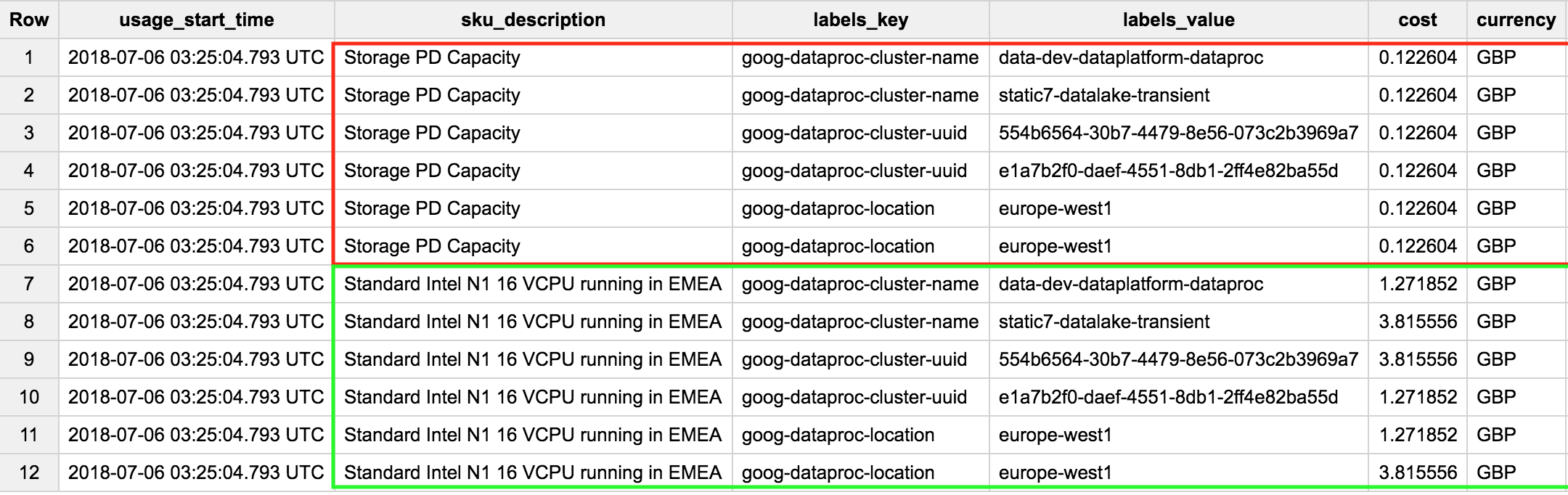
我已经为两种sku的成本画了方框。让我们看看在EMEA项目中运行的标准英特尔N1 16 VCPU。
我只有两个集群,但这两个集群中的每一个都有三行。原因是每个dataproc集群应用了三个标签,因此成本为1.271852
那么我的简单问题是……我如何获得我的dataproc集群的总成本?我是将所有这些数字相加(从而暗示总成本在所有标签上平分)还是只取其中一个值(暗示每个标签的成本都是重复的)?
这是表达我的问题的另一种方式。此查询是否给出了运行集群data-dev-dataplatent-dataproc一天的总成本:
SELECT sum(cost)
FROM [dh-billing-179310:billing.gcp_billing_export_XXXXXXXX]
WHERE labels.key = "goog-dataproc-cluster-name"
and labels.value = "data-dev-dataplatform-dataproc"
and usage_start_time >= "2018-07-05 00:00:00"
and usage_end_time <= "2018-07-06 00:00:00"
还是我需要包含其他标签才能获得总成本?
在计费导出数据的扁平化视图中,每个标签的成本都是重复的;您应该为任何特定的计算选择一个标签值。如果您尝试计算Dataproc总数,使用Dataproc插入的“goog-dataproc-*”标签可能最方便。
这里的想法是,您可以使用不同的标签集来轻松组织归因于任何给定子项目的与Dataproc相关的总成本,以便您可以根据不同的维度过滤计费查询。
