
我有以下Cypher查询:
MATCH (v:Value)-[:CONTAINS]->(hv:HistoryValue)
WHERE v.id = 13335
WITH hv
ORDER BY hv.createDate DESC
OPTIONAL MATCH (hv)-[:CREATED_BY]->(u:User) WHERE true
WITH COLLECT({userId: u.id, historyValueId: hv.id, historyValue: hv.originalValue, historyValueDescription: hv.description, historyValueCreateDate: hv.createDate}) AS data, count(hv) as count, ceil(toFloat(count(hv)) / 100) as step
RETURN REDUCE(s = [], i IN RANGE(0, count - 1, CASE step WHEN 0 THEN 1 ELSE step END) | s + data[i]) AS result
在第一次访问期间的冷Neo4j数据库上,此查询工作非常慢,但第二次和后续调用工作良好。
这是PROFILE输出:
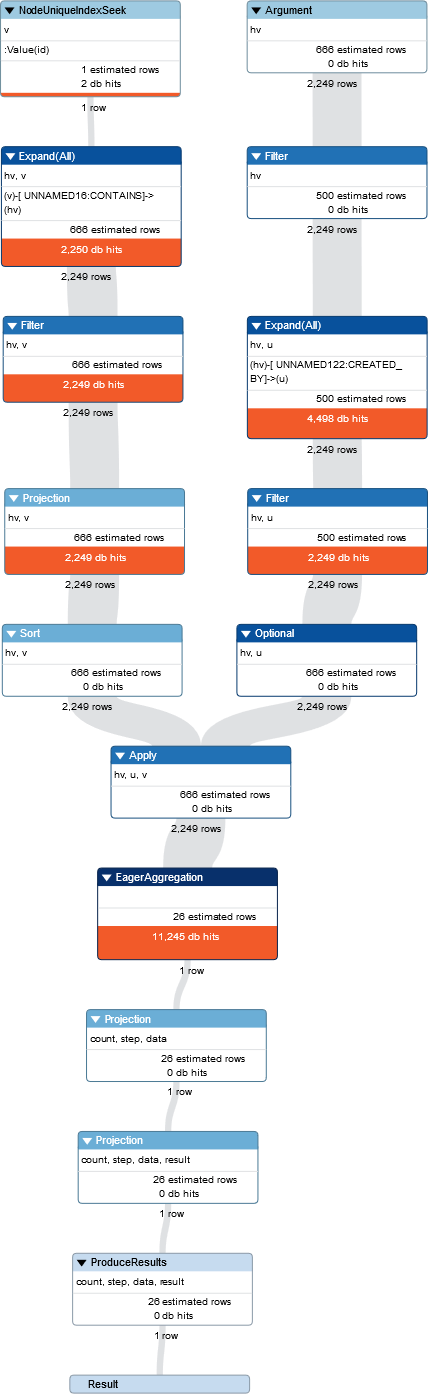
有什么方法可以提高这种查询性能(添加适当的索引等)?
对冷DB的第一次查询相对较慢的主要原因可能是冷DB尚未在内存中缓存任何数据。
在启动DB后立即调用APOC过程apoc.warmup.run可以使您的“第一个”查询更快。
通常,第一个查询需要时间来构建执行计划,也许还有其他一些事情(我不确定列表)。如果问题在于每次使用不同的v.id运行查询时,参数化应该会提供更好的性能。
