
例如,如果我想解决MNIST分类问题,我们有10个输出类。使用PyTorch,我想使用torch. nn.CrossEntropyLoss函数。我必须格式化目标以便它们是one-hotded编码的,或者我可以简单地使用数据集附带的类标签吗?
nn. CrossEntropyLoss需要整数标签。它在内部所做的是,它根本不会对类标签进行单热编码,而是使用标签索引到输出概率向量中,以计算如果您决定使用此类作为最终标签的损失。这个小而重要的细节使计算损失变得更容易,并且与执行one-Hot编码等效,测量每个输出神经元的输出损失,因为输出层中的每个值都将为零,但目标类索引的神经元除外。因此,如果您已经提供了标签,则无需one-hotencode您的数据。
留档对此有更多的见解:https://pytorch.org/docs/master/generated/torch.nn.CrossEntropyLoss.html.在留档中,您将看到目标,它作为输入参数的一部分。这些是您的标签,它们被描述为:
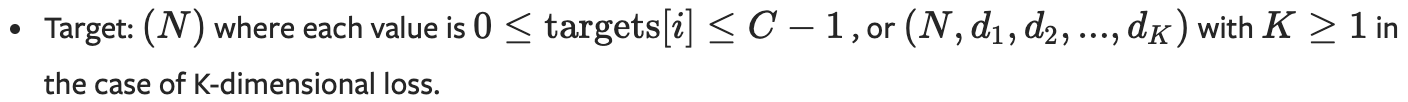
这清楚地显示了输入应该如何形成以及预期的结果。如果您实际上想对数据进行one-Hot编码,则需要使用torch. nn.功能。one_hot。为了最好地复制交叉熵损失在幕后的作用,您还需要nn.功能。log_softmax作为最终输出,并且您必须另外编写自己的损失层,因为PyTorch层都不使用log softmax输入和one-Hot编码目标。但是,nn.CrossEntropyLoss将这两个操作结合在一起,如果您的输出只是类标签,则首选它,因此无需进行转换。
如果您正在加载ImageLoader以从文件夹本身加载数据集,那么PyTorch将自动为您标记它们。您所要做的就是像这样构建文件夹:
|
|__train
| |
| |__1
| |_ 2
| |_ 3
| .
| .
| .
| |_10
|
|__test
|
|__1
|_ 2
|_ 3
.
.
.
|_10
每个类都应该有一个单独的文件夹。如果您从DataFrame加载数据,您可以使用以下代码对它们进行编码:
one_hot = torch.nn.functional.one_hot(target)
