
这段代码将生成一个非常简单的虚拟数据框架,人们在其中填写了一个调查表单:
df2 = pd.DataFrame({
'name':['John','John','John','Rachel','Rachel','Rachel'],
'gender':['Male','Male','Male','Female','Female','Female'],
'age':[40,40,40,39,39,39],
'SurveyQuestion':['Married?','HasKids?','Smokes?','Married?','HasKids?','Smokes?'],
'answers':['Yes','Yes','No','Yes','No','No']
})
输出如下所示:
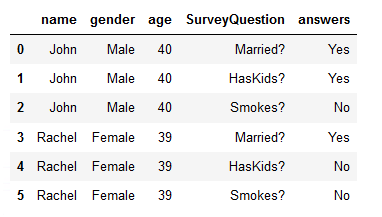
由于表的结构方式,每个问题都有自己的行,我们看到前3列总是包含相同的信息,因为它只是根据填写调查的人重复信息。
最好将数据帧可视化为透视表,类似于以下所示:
df2.pivot(index='name',columns='SurveyQuestion',values='answers')
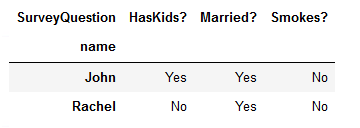
但是,这样做会导致以前的许多列丢失,因为只有一列可以用作索引。
我想知道最直接的方法是什么,不需要额外的重新加入列。
您可以使用df.pivot_table:
In [27]: df2.pivot_table(values='answers', index=['name','gender','age'], columns='SurveyQuestion', aggfunc='first')
Out[27]:
SurveyQuestion HasKids? Married? Smokes?
name gender age
John Male 40 Yes Yes No
Rachel Female 39 No Yes No
或者,您可以将df.pivot与df.set_index一起使用,如下所示:
In [30]: df = df2.set_index(['name', 'gender', 'age'])
In [32]: df.pivot(index=df.index, columns='SurveyQuestion')['answers']
Out[32]:
SurveyQuestion HasKids? Married? Smokes?
name gender age
John Male 40 Yes Yes No
Rachel Female 39 No Yes No
我不确定是否有任何现有的算法可以为您做这件事,但我在我的项目中遇到过类似的问题。
如果您试图压缩表中的行,首先需要确保每个人都可以应用相同的列。 例如,如果你没有问“haskids?”,你就不能合理地这样做。 问瑞秋一个问题,除非你包括一个N/A选项。
在此之后,按某个唯一的ID对表进行排序,这样任何重复的人都将在表中彼此紧挨着。
然后遍历该表,每次点击与上一个相同的行时,获取它所具有的任何唯一信息,将其添加到该人员的原始行中,并删除此重复。 如果这是针对整个表完成的,那么您应该得到您的枢轴。
