
我正在尝试了解RIDL漏洞类。
这是一类能够从各种微架构缓冲区读取陈旧数据的漏洞。
今天已知的漏洞利用:LFB、加载端口、eMC和存储缓冲区。
本文主要关注LFB。
我不明白为什么CPU会满足LFB中陈旧数据的负载。
我可以想象,如果负载在L1d中命中,它会在内部“重放”,直到L1d将数据带入LFB,通知OoO核心停止“重放”它(因为读取的数据现在有效)。
然而,我不确定“重放”实际上是什么意思。
我认为负载被调度到一个具有负载能力的端口,然后记录在负载缓冲区中(在MOB中),最终根据需要保持,直到它们的数据可用(如L1所示)。所以我不确定“重放”是如何发挥作用的,此外,为了让RIDL工作,每次尝试“播放”负载也应该解除屏蔽相关指令。
这对我来说似乎很奇怪,因为CPU需要跟踪加载正确完成后重放哪些指令。
关于RIDL的论文使用此代码作为示例(不幸的是,我不得不将其粘贴为图像,因为PDF布局不允许我复制它):

它可以工作的唯一原因是,如果CPU将首先在第6行用陈旧的数据满足负载,然后重放它。
具体来说,我们可能期望两次访问是快速的,而不仅仅是泄漏信息对应的一次。毕竟,当处理器发现自己的错误并在第6行以正确的值重新启动时,程序也将访问具有此索引的缓冲区。
但是我希望CPU在转发LFB(或任何其他内部缓冲区)中的数据之前检查加载的地址。
除非CPU实际上重复执行加载,直到它检测到加载的数据现在是有效的(即重放)。但是,同样,为什么每次尝试都会解除屏蔽依赖指令?
如果存在重放机制,它究竟是如何工作的,以及它如何与RIDL漏洞相互作用?
我不认为来自RS的负载重放与RIDL攻击有关。因此,我将根据我对RIDL论文中提供的信息的理解、英特尔对这些漏洞的分析以及相关专利,讨论我认为正在发生的事情,而不是解释什么是负载重放(@Peter的回答是一个很好的起点)。
行填充缓冲区是L1D缓存中的硬件结构,用于保存缓存中未命中的内存请求和I/O请求,直到它们得到服务。当所需的缓存行填充到L1D数据数组中时,可缓存请求会得到服务。当驱逐写合并缓冲区的任何条件发生时,写合并写入会得到服务(如手册中所述)。UC或I/O请求在发送到L2缓存时得到服务(这会尽快发生)。
参考RIDL论文的图4。用于产生这些结果的实验工作如下:
我不清楚图4中的Y轴代表什么。我的理解是,它表示每秒从隐蔽通道获取到缓存层次结构(第10行)的行数,其中数组中行的索引等于受害者写入的值。
如果内存位置是WB类型的,当受害线程将已知值写入内存位置时,该行将被填充到L1D缓存中。如果内存位置是WT类型的,当受害线程将已知值写入内存位置时,该行将不会被填充到L1D缓存中。但是,在第一次从该行读取时,它会被填充。所以在这两种情况下并且没有CLFLUSH,受害者线程的大多数负载都会命中缓存。
有趣的是,在WB和WT情况下,陈旧数据转发的频率远低于所有其他情况。这可以解释为,在这些情况下,受害者的吞吐量要高得多,实验可能会提前终止。
在所有其他情况下(WC、UC和所有具有刷新的类型),缓存中的每个加载都未命中,必须通过LFB从主存储器获取数据到加载缓冲区。发生以下事件序列:
如果攻击者的负载没有故障/辅助,LFB将从MMU收到一个有效的物理地址,并执行正确性所需的所有检查。这就是负载必须故障/辅助的原因。
本文的以下引用讨论了如何在同一线程中执行RIDL攻击:
我们在没有SMT的情况下执行RIDL攻击,方法是在我们自己的线程中写入值并观察我们从同一线程泄漏的值。图3显示,如果我们不写入值(“没有受害者”),我们只泄漏零,但是受害者和攻击者在同一个硬件线程中运行(例如,在沙盒中),我们几乎在所有情况下都会泄漏秘密值。
我认为在这个实验中没有特权级别的变化。受害者和攻击者在同一个硬件线程上的同一个OS线程中运行。当从受害者返回给攻击者时,来自(尤其是来自商店)的LFB中仍然可能存在一些未完成的请求。请注意,在RIDL论文中,KPTI在所有实验中都是启用的(与Fallout论文相反)。
除了从LFB泄漏数据外,MLPDS显示数据也可能从负载端口缓冲区泄漏。其中包括行分割缓冲区和用于大小大于8字节的负载的缓冲区(我认为当负载uop的大小大于负载端口的大小时需要这些缓冲区,例如,在SnB/IvB上的AVX256b占用端口2个周期)。
图5中的WB情况(无刷新)也很有趣。在这个实验中,受害线程向4个不同的缓存行写入4个不同的值,而不是从同一个缓存行读取。图中显示,在WB情况下,只有写入最后一个缓存行的数据被泄露给攻击者。解释可能取决于缓存行在循环的不同迭代中是否不同,不幸的是,这在论文中并不清楚。论文说:
对于没有刷新的WB,存在仅用于最后一个高速缓存行的信号,这表明CPU在将数据存储在高速缓存中之前在LFB的单个条目中执行写组合。
在将数据存储在缓存中之前,对不同缓存行的写入如何组合在同一个LFB中?这毫无意义。LFB可以保存单个缓存行和单个物理地址。这样组合写入是不可能的。可能发生的情况是,WB写入正在为其RFO请求分配的LFB中写入。当无效的物理地址被传输到LFB进行比较时,数据可能总是从最后分配的LFB中提供。这将解释为什么只有第四个存储写入的值被泄露。
有关MDS缓解措施的信息,请参阅:什么是新的MDS攻击,以及如何缓解它们?。我在那里的回答只讨论了基于Intel微码更新的缓解措施(而不是非常有趣的“软件序列”)。
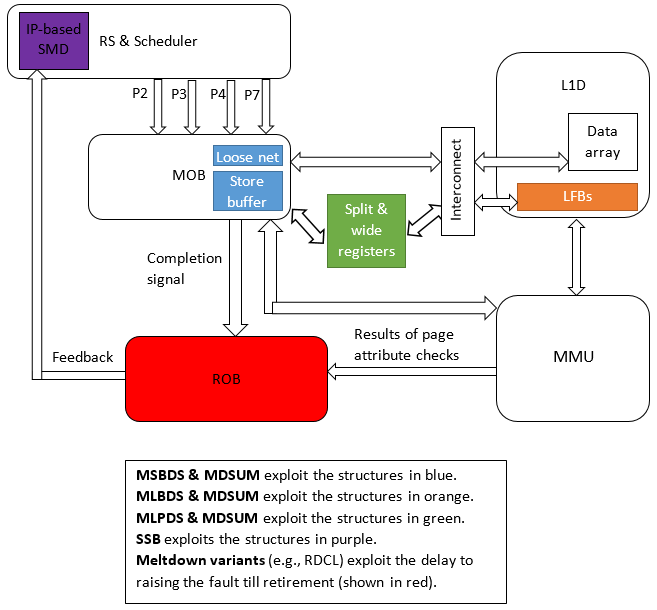
下图显示了使用数据推测的易受攻击的结构。
replay=从RS(调度程序)再次调度。(这不是你整个问题的完整答案,只是关于什么是重播的部分。尽管我认为这涵盖了大部分内容,包括解除阻塞依赖的uops。)
请参阅聊天中的讨论-uops依赖于拆分或缓存未命中的负载得到重放,但不是负载本身。(除非负载在循环中依赖于自身,就像我一直在测试中所做的那样
事实证明,缓存未命中的负载不仅仅是坐在负载缓冲区中,当数据到达时唤醒依赖的uops。调度程序必须重新调度负载uop以实际读取数据并写回物理寄存器。(并将其放在转发网络上,依赖的uops可以在下一个周期读取它。)
所以L1未命中/L2命中将导致2倍的负载uops被调度。(调度器是乐观的,并且L2是核心的,因此L2命中的预期延迟是固定的,与非核心响应的时间不同。如果调度器继续对从L3到达某个时间的数据保持乐观,则IDK。)
RIDL论文提供了一些有趣的证据,表明load uops确实直接与LFB交互,而不是等待传入数据放入L1d并从那里读取它。
对于缓存行拆分负载,我们可以在实践中最容易地观察到重放,因为重复引起重放甚至比缓存未命中更微不足道,占用更少的代码。uops_dispatched_port.port_2和port_3的计数对于只拆分负载的循环来说大约是两倍。(我在Skylake上的实践中验证了这一点,使用的循环和测试过程与我如何准确地基准x86_64上未对齐的访问速度基本相同)
检测到拆分的负载(只有在地址计算后才有可能)将为数据的第一部分进行加载,而不是将成功完成通知回RS,将此结果放入拆分缓冲区1中,以便在uop第二次分派时与来自第二个缓存行的数据连接。(假设这两个时间都不是缓存未命中,否则也将需要重放。)
当负载uop分派时,调度程序预计它将在L1d中命中并分派依赖的uops,以便它们可以在负载将它们放在该总线上的周期内从转发网络读取结果。
如果没有发生这种情况(因为加载数据还没有准备好),依赖的uops也必须重放。同样,IIRC这可以通过调度到端口的perf计数器观察到。
现有Q
脚注1:
我们知道拆分缓冲区的数量有限;有一个ld_blocks。no_sr计数器,用于因缺少一个而停止的负载。我推断它们在加载端口,因为这是有道理的。重新调度相同的负载uop将把它发送到相同的加载端口,因为uops在发布/重命名时被分配给端口。尽管可能有一个共享的拆分缓冲区池。
乐观调度是产生问题的机制的一部分。更明显的问题是让稍后uops的执行看到来自LFB的“垃圾”内部值,就像在Meltdown中一样。
http://blog.stuffedcow.net/2018/05/meltdown-microarchitecture/甚至表明,PPro中的崩溃负载暴露了各种微架构状态,就像最新处理器中仍然存在的这个漏洞一样。
奔腾Pro从字面上理解“加载值是不关心的”。对于所有禁止的加载,加载单元完成并产生一个值,该值似乎是从处理器的各个部分获取的各种值。值各不相同,可能是不确定的。返回的值似乎都不是内存数据,因此奔腾Pro似乎不容易受到Meltdown的影响。
可识别的值包括负载的PTE(至少在最近几年,它本身被认为是特权信息)、第12个最近的存储值(存储队列有12个条目),以及很少来自某个地方的段描述符。
(后来的CPU,从Core 2开始,暴露L1d缓存中的值;这就是Meltdown漏洞本身。但是PPro/PII/PIII不容易受到Meltdown的攻击。在这种情况下,它显然容易受到RIDL攻击。)
因此,这是相同的英特尔设计理念,将微架构状态暴露给推测执行。
在硬件中将其压缩到0应该是一个简单的解决方案;负载端口已经知道它不成功,因此根据成功/失败屏蔽负载数据应该只希望增加几个额外的门延迟,并且可以在不限制时钟速度的情况下实现。(除非负载端口中的最后一个管道阶段已经是CPU频率的关键路径。)
因此,对于未来的CPU来说,硬件可能是一个简单而廉价的解决方案,但对于现有的CPU来说,微码和软件很难缓解。
