
在一个自学项目中,我借助以下代码测量内存的带宽(此处转述,整个代码如下):
unsigned int doit(const std::vector<unsigned int> &mem){
const size_t BLOCK_SIZE=16;
size_t n = mem.size();
unsigned int result=0;
for(size_t i=0;i<n;i+=BLOCK_SIZE){
result+=mem[i];
}
return result;
}
//... initialize mem, result and so on
int NITER = 200;
//... measure time of
for(int i=0;i<NITER;i++)
resul+=doit(mem)
BLOCK_SIZE的选择方式是这样的,每次整数加法都会获取整个64字节的缓存行。我的机器(Intel Broadwell)每个整数加法需要大约0.35纳秒,所以上面的代码可能会使高达182GB/s的带宽饱和(这个值只是一个上限,可能非常偏离,重要的是不同大小的带宽比率)。代码是用g和-O3编译的。
改变向量的大小,我可以观察到L1(*)-、L2-、L3缓存和RAM内存的预期带宽:
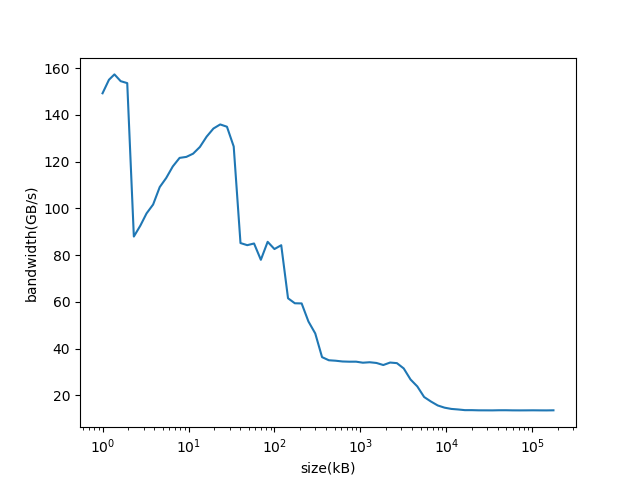
但是,有一个影响我真的很难解释:对于大约2 kB的大小,L1缓存的测量带宽崩溃,这里的分辨率更高:

我可以在我可以访问的所有机器(具有Intel Broadwell和Intel Haswell处理器)上重现结果。
我的问题:内存大小在2KB左右的性能崩溃的原因是什么?
(*)我希望我理解正确,对于L1缓存,读取/传输的不是64个字节,而是每次添加仅4个字节(没有更快的缓存必须填充缓存行),因此L1的绘制带宽只是上限,而不是坏宽度本身。
编辑:当内部for循环中的步长被选择为
即当内部循环由大约31-35步/次读取组成时。这意味着崩溃不是由于内存大小,而是由于内部循环中的步数。
它可以用分支未命中来解释,如@user10605163的伟大回答所示。
列出以重现结果
带宽. cpp:
#include <vector>
#include <chrono>
#include <iostream>
#include <algorithm>
//returns minimal time needed for one execution in seconds:
template<typename Fun>
double timeit(Fun&& stmt, int repeat, int number)
{
std::vector<double> times;
for(int i=0;i<repeat;i++){
auto begin = std::chrono::high_resolution_clock::now();
for(int i=0;i<number;i++){
stmt();
}
auto end = std::chrono::high_resolution_clock::now();
double time = std::chrono::duration_cast<std::chrono::nanoseconds>(end-begin).count()/1e9/number;
times.push_back(time);
}
return *std::min_element(times.begin(), times.end());
}
const int NITER=200;
const int NTRIES=5;
const size_t BLOCK_SIZE=16;
struct Worker{
std::vector<unsigned int> &mem;
size_t n;
unsigned int result;
void operator()(){
for(size_t i=0;i<n;i+=BLOCK_SIZE){
result+=mem[i];
}
}
Worker(std::vector<unsigned int> &mem_):
mem(mem_), n(mem.size()), result(1)
{}
};
double PREVENT_OPTIMIZATION=0.0;
double get_size_in_kB(int SIZE){
return SIZE*sizeof(int)/(1024.0);
}
double get_speed_in_GB_per_sec(int SIZE){
std::vector<unsigned int> vals(SIZE, 42);
Worker worker(vals);
double time=timeit(worker, NTRIES, NITER);
PREVENT_OPTIMIZATION+=worker.result;
return get_size_in_kB(SIZE)/(1024*1024)/time;
}
int main(){
int size=BLOCK_SIZE*16;
std::cout<<"size(kB),bandwidth(GB/s)\n";
while(size<10e3){
std::cout<<get_size_in_kB(size)<<","<<get_speed_in_GB_per_sec(size)<<"\n";
size=(static_cast<int>(size+BLOCK_SIZE)/BLOCK_SIZE)*BLOCK_SIZE;
}
//ensure that nothing is optimized away:
std::cerr<<"Sum: "<<PREVENT_OPTIMIZATION<<"\n";
}
create_report.py:
import sys
import pandas as pd
import matplotlib.pyplot as plt
input_file=sys.argv[1]
output_file=input_file[0:-3]+'png'
data=pd.read_csv(input_file)
labels=list(data)
plt.plot(data[labels[0]], data[labels[1]], label="my laptop")
plt.xlabel(labels[0])
plt.ylabel(labels[1])
plt.savefig(output_file)
plt.close()
构建/运行/创建报告:
>>> g++ -O3 -std=c++11 bandwidth.cpp -o bandwidth
>>> ./bandwidth > report.txt
>>> python create_report.py report.txt
# image is in report.png
我稍微更改了值:NITER=100000和NTRIES=1以获得较少噪音的结果。
我现在没有Broadwell可用,但是我在我的咖啡湖上尝试了您的代码,并得到了性能下降,不是2KB,而是大约4.5KB。此外,我发现吞吐量的不稳定行为略高于2KB。

这里的红线是来自perf stat-e分支点指令,分支点未命中的结果,给出了未正确预测的分支的比例(以百分比为单位,右轴)。如您所见,两者之间存在明显的反相关关系。
查看更详细的perf报告,我发现基本上所有这些分支错误预测都发生在Worker::运算符()中最内部的循环中。如果循环分支的已采取/未采取模式变得太长,分支预测器将无法跟踪它,因此内部循环的退出分支将被错误预测,导致吞吐量急剧下降。随着迭代次数的进一步增加,这种单一错误预测的影响将变得不那么重要,导致吞吐量恢复缓慢。
有关投放前不稳定行为的更多信息,请参阅下面@PeterCordes的评论。
在任何情况下,避免分支错误预测的最佳方法是避免分支,所以我手动在Worker::Operator()中展开循环,例如:
void operator()(){
for(size_t i=0;i+3*BLOCK_SIZE<n;i+=BLOCK_SIZE*4){
result+=mem[i];
result+=mem[i+BLOCK_SIZE];
result+=mem[i+2*BLOCK_SIZE];
result+=mem[i+3*BLOCK_SIZE];
}
}
展开2、3、4、6或8次迭代给出了下面的结果。请注意,我没有纠正由于展开而被忽略的向量末尾的块。因此应该忽略蓝线中的周期性峰值,周期模式的下界基线是实际带宽。

正如您所看到的,分支错误预测的比例并没有真正改变,但是由于未展开迭代的因子减少了分支的总数,它们将不再对性能有很大的贡献。
还有一个额外的好处是,如果循环展开,处理器可以更自由地进行无序计算。
如果这应该有实际应用,我建议尝试给热循环一个编译时固定的迭代次数或一些可分性保证,这样(也许有一些额外的提示)编译器可以决定要展开的最佳迭代次数。
可能与此无关,但您的Linux机器可能会以CPU频率运行。我知道Ubuntu 18有一个在功率和性能之间平衡的gouverner。您还想使用进程亲和性,以确保它在运行时不会迁移到不同的内核。
