
我正在从csv文件中读取2个数据帧。但是,当我连接这2个数据帧时,由于它们之间的连接,我得到了一个空数据集。
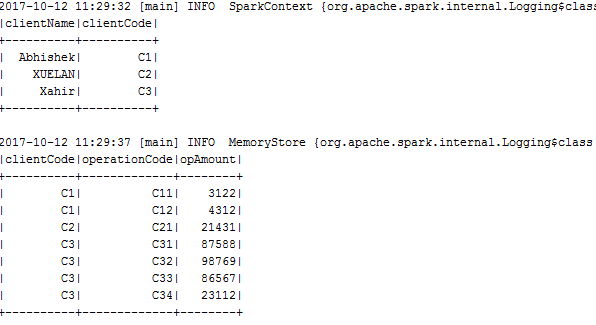
这是2个数据帧。
val dfAverage = amount.join(client,"clientCode")
.groupBy(client("clientName")).agg(avg(amount("opAmount"))
.as("average"))
.select("clientName","average")
这是Join的代码片段。结果我得到了一个空的dataFrame,但模式是正确的。

由于我是Scala和Spark的新手,我需要帮助来解决这个简单的问题。
提前感谢。
import org.apache.spark.sql.functions._
val client = sc.parallelize(Seq(
("Abhishek", "C1"),
("XUELAN", "C2"),
("Xahir", "C3")
)).toDF("ClientName", "ClientCode")
client.show()
+----------+----------+
|ClientName|ClientCode|
+----------+----------+
| Abhishek| C1|
| XUELAN| C2|
| Xahir| C3|
+----------+----------+
val amount = sc.parallelize(Seq(
("C1", "C11",3122l),
("C1", "C12",4312l),
("C2", "C21",21431l),
("C2", "C31",87588l),
("C3", "C32",98769l),
("C3", "C33",86567l),
("C3", "C34",23112l)
)).toDF("ClientCode", "OperationCode" ,"opAmount")
amount.show()
+----------+-------------+--------+
|ClientCode|OperationCode|opAmount|
+----------+-------------+--------+
| C1| C11| 3122|
| C1| C12| 4312|
| C2| C21| 21431|
| C2| C31| 87588|
| C3| C32| 98769|
| C3| C33| 86567|
| C3| C34| 23112|
+----------+-------------+--------+
val dfAverage = amount.join(client,"clientCode") .groupBy(client("clientName"))
.agg(avg(amount("opAmount")).as("average"))
.select("clientName","average")
dfAverage.show()
+----------+-----------------+
|clientName| average|
+----------+-----------------+
| Abhishek| 3717.0|
| Xahir|69482.66666666667|
| XUELAN| 54509.5|
+----------+-----------------+
或
import sqlContext.implicits._
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
client.createOrReplaceTempView("client")
amount.createOrReplaceTempView("amount")
val result = spark.sqlContext.sql("SELECT
client.ClientName,avg(amount.opAmount)as average FROM amount JOIN client on
amount.ClientCode=client.ClientCode GROUP BY client.ClientName")
+----------+-----------------+
|ClientName| average|
+----------+-----------------+
| Abhishek| 3717.0|
| Xahir|69482.66666666667|
| XUELAN| 54509.5|
+----------+-----------------+
