
我有一个在数据流运行器上运行的光束流作业。它从PubSub加载请求(使用Python的apache_beam.io. ReadFromPubSub),然后从BigTable获取数据,对数据进行大量计算并再次写入PubSub。
with beam.Pipeline(options=pipeline_options) as pipeline:
(
pipeline
| "Receive" >> beam.io.ReadFromPubSub(topic=TOPIC_READ)
| "Parse" >> beam.ParDo(Parse())
| "Fetch" >> beam.ParDo(FetchFromBigtable(project, args.bt_instance, args.bt_par, args.bt_batch))
| "Process" >> beam.ParDo(Process())
| "Publish" >> beam.io.WriteToPubSub(topic=TOPIC_WRITE)
)
基本上我不需要任何窗口,我只想限制在一台机器上并行处理的元素数量(即通过工作人员的数量控制并行度)。否则在繁重的计算过程中会导致内存溢出,我还需要限制BigTable请求的速率。
我使用的是标准的2CPU机器,所以我希望它能并行处理2个elemet-我还设置了--number_of_worker_harness_threads=2和--sdk_worker_parallelism=1。出于某种原因,尽管我看到许多元素由多个线程并行处理,这会导致内存和速率限制问题。我猜这些是根据日志并行处理的捆绑包(例如work:process_bundle-105)。
我试图通过在process Element中使用信号量来破解它(每个DoFN实例只处理一个元素)并且它有效,但是自动缩放不会启动,它看起来像一个纯粹的黑客攻击,可能会产生其他后果。
你会推荐什么?我如何限制要处理的并行包的数量?理想情况下每个工作线束线程只有一个包?光束/数据流是否适合此类用例,或者使用带有自动缩放的普通kubernetes来实现它更好?
编辑:
在光束SDK上运行
我想限制并行性,但是我没有很好地描述导致我得出这个结论的症状。
Fetch阶段超时Deadline of 60.0s exceeded while calling functools.partial(<bound method PartialRowsData._read_next of <google.cloud.bigtable.row_data.PartialRowsData object at 0x7f16b405ba50>>)
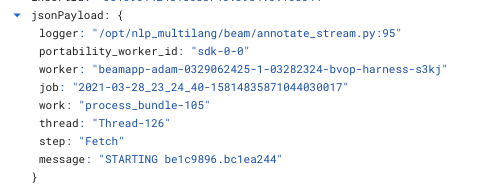
下面是一个worker在Process阶段(单线程)处理1个元素之前和之后记录的日志,由jsonPayload. worker和jsonPayload过滤。portability_worker_id(即我希望这些应该是来自一个容器的日志)。我可以看到在一瞬间处理超过12个元素。
数据流每个核心启动一个SDK工作容器,所以在你的情况下,每台机器将有2个工作容器(进程)。每个工作进程都有一个无限的线程池来处理捆绑包,但我认为由于python GIL,一次只有一个捆绑包被一个线程处理。
您可以使用-实验no_use_multiple_sdk_containers将sdk容器编号限制为1(因为您的用例似乎不太关心吞吐量)。
我已经通过使用状态处理成功地解决了Dataflow和Elasticsearch的类似问题。如果您的接收器跟不上管道其余部分的速度,您可以使用GroupIntoBatches来减少并行性。
据我所知,状态是由运行器在每个键每个窗口的基础上维护的。要使用有状态处理,您的数据将需要有键。这些键可以是任意的,并且被您用于消费元素的DoFn忽略。
你提到你不需要窗口,如果你目前没有使用任何窗口,这意味着你使用的是默认的单数全局窗口。在这种情况下,无论你任意分配给数据的不同键的数量是保持的并行化状态的最大数量。请注意,这个解决方案不能移植到所有运行器,因为所有运行器都不全局支持状态处理。
