
我有一个在Dataflow中运行的无界Apache Beam管道,它执行一组非常简单的指令:
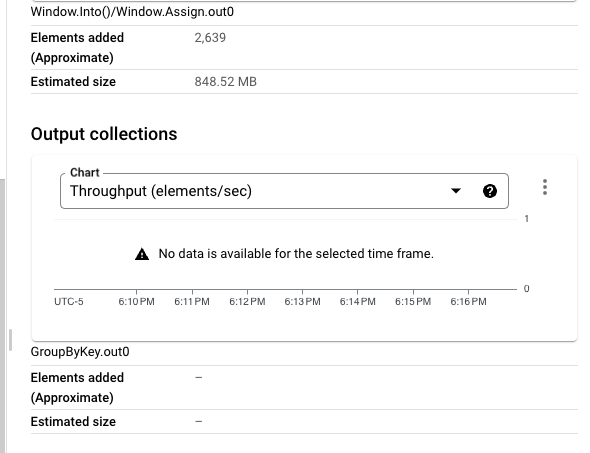
我希望看到的是,当第2步开始产生数据时,每个KV都会在当前3秒的固定窗口中被标记在一起,这样它就可以在第4步中与第2步中定义的键一起批处理。然而,我看到的是数据没有流过GroupByKey步骤(见下图),这对我来说意味着我没有正确设置窗口。
p.apply("Reading input",
PubsubIO.readMessages()
.fromSubscription(INPUT_SUBSCRIPTION)
.withDeadLetterTopic(DL_TOPIC))
.apply("Reading data",
ParDo.of(new ReadPlanFromBqFn()))
.apply(Window.into(FixedWindows.of(Duration.standardSeconds(3))))
.apply(GroupByKey.create())
.apply("Splitting store/item combinations",
ParDo.of(new SplitItemCombos()))
我错过了什么?
更新:
以下是我尝试过的其他事情的列表:
.apply(GroupIntoBatches.<Integer, FieldValueList>ofSize(100)
.withMaxBufferingDuration(Duration.standardSeconds(1)))
.apply(Window.<FieldValueList>into(FixedWindows.of(Duration.standardSeconds(1)))
.triggering(Repeatedly.forever(AfterWatermark.pastEndOfWindow()))
.withAllowedLateness(Duration.standardSeconds(3))
.discardingFiredPanes()
)
我认为这里缺少触发器,它将告诉Beam窗口何时真正触发,而不仅仅是它们将如何组合在一起(窗口)。
看看https://beam.apache.org/documentation/programming-guide/#setting-a-trigger.
