
我已经运行了下面的代码522 gzip文件的大小100 GB和解压后,它将是大约320 GB的数据和数据,并将输出写入GCS.我已经使用了n1标准的机器和地区的输入,输出都照顾和工作成本我约17$,这是半小时的数据,所以我真的需要做一些成本优化在这里非常糟糕。
我从以下查询中获得的成本
SELECT l.value AS JobID, ROUND(SUM(cost),3) AS JobCost
FROM `PROJECT.gcp_billing_data.gcp_billing_export_v1_{}` bill,
UNNEST(bill.labels) l
WHERE service.description = 'Cloud Dataflow' and l.key = 'goog-dataflow-job-id' and
extract(date from _PARTITIONTIME) > "2020-12-31"
GROUP BY 1
完整的代码
import time
import sys
import argparse
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import SetupOptions
import csv
import base64
from google.protobuf import timestamp_pb2
from google.protobuf.json_format import MessageToDict
from google.protobuf.json_format import MessageToJson
import io
import logging
from io import StringIO
from google.cloud import storage
import json
###PROTOBUF CLASS
from otherfiles import processor_pb2
class ConvertToJson(beam.DoFn):
def process(self, message, *args, **kwargs):
import base64
from otherfiles import processor_pb2
from google.protobuf.json_format import MessageToDict
from google.protobuf.json_format import MessageToJson
import json
if (len(message) >= 4):
b64ProtoData = message[2]
totalProcessorBids = int(message[3] if message[3] and message[3] is not None else 0);
b64ProtoData = b64ProtoData.replace('_', '/')
b64ProtoData = b64ProtoData.replace('*', '=')
b64ProtoData = b64ProtoData.replace('-', '+')
finalbunary = base64.b64decode(b64ProtoData)
log = processor_pb2.ProcessorLogProto()
log.ParseFromString(finalbunary)
#print(log)
jsonObj = MessageToDict(log,preserving_proto_field_name=True)
jsonObj["totalProcessorBids"] = totalProcessorBids
#wjdata = json.dumps(jsonObj)
print(jsonObj)
return [jsonObj]
else:
pass
class ParseFile(beam.DoFn):
def process(self, element, *args, **kwargs):
import csv
for line in csv.reader([element], quotechar='"', delimiter='\t', quoting=csv.QUOTE_ALL, skipinitialspace=True):
#print (line)
return [line]
def run():
parser = argparse.ArgumentParser()
parser.add_argument("--input", dest="input", required=False)
parser.add_argument("--output", dest="output", required=False)
parser.add_argument("--bucket", dest="bucket", required=True)
parser.add_argument("--bfilename", dest="bfilename", required=True)
app_args, pipeline_args = parser.parse_known_args()
#pipeline_args.extend(['--runner=DirectRunner'])
pipeline_options = PipelineOptions(pipeline_args)
pipeline_options.view_as(SetupOptions).save_main_session = True
bucket_input=app_args.bucket
bfilename=app_args.bfilename
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_input)
blob = bucket.blob(bfilename)
blob = blob.download_as_string()
blob = blob.decode('utf-8')
blob = StringIO(blob)
pqueue = []
names = csv.reader(blob)
for i,filename in enumerate(names):
if filename and filename[0]:
pqueue.append(filename[0])
with beam.Pipeline(options=pipeline_options) as p:
if(len(pqueue)>0):
input_list=app_args.input
output_list=app_args.output
events = ( p | "create PCol from list" >> beam.Create(pqueue)
| "read files" >> beam.io.textio.ReadAllFromText()
| "Transform" >> beam.ParDo(ParseFile())
| "Convert To JSON" >> beam.ParDo(ConvertToJson())
| "Write to BQ" >> beam.io.WriteToBigQuery(
table='TABLE',
dataset='DATASET',
project='PROJECT',
schema="dataevent:STRING",
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
insert_retry_strategy=RetryStrategy.RETRY_ON_TRANSIENT_ERROR,
custom_gcs_temp_location='gs://BUCKET/gcs-temp-to-bq/',
method='FILE_LOADS'))
##bigquery failed rows NOT WORKING so commented
#(events[beam.io.gcp.bigquery.BigQueryWriteFn.FAILED_ROWS] | "Bad lines" >> beam.io.textio.WriteToText("error_log.txt"))
##WRITING TO GCS
#printFileConetent | "Write TExt" >> beam.io.WriteToText(output_list+"file_",file_name_suffix=".json",num_shards=1, append_trailing_newlines = True)
if __name__ == '__main__':
logging.getLogger().setLevel(logging.INFO)
run()
这项工作花了大约49分钟
我尝试过的事情: 1)对于avro,生成的模式需要在JSON的proto文件,并尝试下面的代码将字典转换为avro msg,但它需要时间,因为字典的大小更多。schema_separated=是一个avroJSON模式,它工作得很好
with beam.Pipeline(options=pipeline_options) as p:
if(len(pqueue)>0):
input_list=app_args.input
output_list=app_args.output
p1 = p | "create PCol from list" >> beam.Create(pqueue)
readListofFiles=p1 | "read files" >> beam.io.textio.ReadAllFromText()
parsingProtoFile = readListofFiles | "Transform" >> beam.ParDo(ParseFile())
printFileConetent = parsingProtoFile | "Convert To JSON" >> beam.ParDo(ConvertToJson())
compressIdc=True
use_fastavro=True
printFileConetent | 'write_fastavro' >> WriteToAvro(
output_list+"file_",
# '/tmp/dataflow/{}/{}'.format(
# 'demo', 'output'),
# parse_schema(json.loads(SCHEMA_STRING)),
parse_schema(schema_separated),
use_fastavro=use_fastavro,
file_name_suffix='.avro',
codec=('deflate' if compressIdc else 'null'),
)
在主代码中,我试图将JSON记录作为字符串插入到bigquery表中,这样我就可以在bigquery中使用JSON函数来提取数据,这也不顺利,并得到下面的错误。
message:'读取数据时出错,错误消息:JSON表遇到太多错误,放弃。行: 1;错误:1。请查看错误[]集合了解更多详细信息。'原因:'无效'
尝试将上述JSON字典插入bigquery,为表提供JSON模式,并且工作正常
现在的挑战是反序列化原型后的大小JSON字典增加了一倍,成本将通过处理多少数据在数据流中计算
我正在尝试和阅读大量的文章来完成这项工作,如果它有效,那么我就可以使它稳定地用于生产。
样本JSON记录。
{'timestamp': '1609286400', 'bidResponseId': '5febc300000115cd054b9fd6840a5af1', 'aggregatorId': '1', 'userId': '7567d74e-2e43-45f4-a42a-8224798bb0dd', 'uniqueResponseId': '', 'adserverId': '1002418', 'dataVersion': '1609285802', 'geoInfo': {'country': '101', 'region': '122', 'city': '11605', 'timezone': '420'}, 'clientInfo': {'os': '4', 'browser': '1', 'remoteIp': '36.70.64.0'}, 'adRequestInfo': {'requestingPage': 'com.opera.mini.native', 'siteId': '557243954', 'foldPosition': '2', 'adSlotId': '1', 'isTest': False, 'opType': 'TYPE_LEARNING', 'mediaType': 'BANNER'}, 'userSegments': [{'id': '2029660', 'weight': -1.0, 'recency': '1052208'}, {'id': '2034588', 'weight': -1.0, 'recency': '-18101'}, {'id': '2029658', 'weight': -1.0, 'recency': '744251'}, {'id': '2031067', 'weight': -1.0, 'recency': '1162398'}, {'id': '2029659', 'weight': -1.0, 'recency': '862833'}, {'id': '2033498', 'weight': -1.0, 'recency': '802749'}, {'id': '2016729', 'weight': -1.0, 'recency': '1620540'}, {'id': '2034584', 'weight': -1.0, 'recency': '111571'}, {'id': '2028182', 'weight': -1.0, 'recency': '744251'}, {'id': '2016726', 'weight': -1.0, 'recency': '1620540'}, {'id': '2028183', 'weight': -1.0, 'recency': '744251'}, {'id': '2028178', 'weight': -1.0, 'recency': '862833'}, {'id': '2016722', 'weight': -1.0, 'recency': '1675814'}, {'id': '2029587', 'weight': -1.0, 'recency': '38160'}, {'id': '2028177', 'weight': -1.0, 'recency': '862833'}, {'id': '2016719', 'weight': -1.0, 'recency': '1675814'}, {'id': '2027404', 'weight': -1.0, 'recency': '139031'}, {'id': '2028172', 'weight': -1.0, 'recency': '1052208'}, {'id': '2028173', 'weight': -1.0, 'recency': '1052208'}, {'id': '2034058', 'weight': -1.0, 'recency': '1191459'}, {'id': '2016712', 'weight': -1.0, 'recency': '1809526'}, {'id': '2030025', 'weight': -1.0, 'recency': '1162401'}, {'id': '2015235', 'weight': -1.0, 'recency': '139031'}, {'id': '2027712', 'weight': -1.0, 'recency': '139031'}, {'id': '2032447', 'weight': -1.0, 'recency': '7313670'}, {'id': '2034815', 'weight': -1.0, 'recency': '586825'}, {'id': '2034811', 'weight': -1.0, 'recency': '659366'}, {'id': '2030004', 'weight': -1.0, 'recency': '139031'}, {'id': '2027316', 'weight': -1.0, 'recency': '1620540'}, {'id': '2033141', 'weight': -1.0, 'recency': '7313670'}, {'id': '2034736', 'weight': -1.0, 'recency': '308252'}, {'id': '2029804', 'weight': -1.0, 'recency': '307938'}, {'id': '2030188', 'weight': -1.0, 'recency': '3591519'}, {'id': '2033449', 'weight': -1.0, 'recency': '1620540'}, {'id': '2029672', 'weight': -1.0, 'recency': '1441083'}, {'id': '2029664', 'weight': -1.0, 'recency': '636630'}], 'perfInfo': {'timeTotal': '2171', 'timeBidInitialize': '0', 'timeProcessDatastore': '0', 'timeGetCandidates': '0', 'timeAdFiltering': '0', 'timeEcpmComputation': '0', 'timeBidComputation': '0', 'timeAdSelection': '0', 'timeBidSubmit': '0', 'timeTFQuery': '0', 'timeVWQuery': '8'}, 'learningPercent': 0.10000000149011612, 'pageLanguageId': '0', 'sspUserId': 'CAESECHFlNeuUm16IYThguoQ8ck_1', 'minEcpm': 0.12999999523162842, 'adSpotId': '1', 'creativeSizes': [{'width': '7', 'height': '7'}], 'pageTypeId': '0', 'numSlots': '0', 'eligibleLIs': [{'type': 'TYPE_OPTIMIZED', 'liIds': [{'id': 44005, 'reason': '12', 'creative_id': 121574, 'bid_amount': 8.403361132251052e-08}, {'id': 46938, 'reason': '12', 'creative_id': 124916, 'bid_amount': 8.403361132251052e-06}, {'id': 54450, 'reason': '12', 'creative_id': 124916, 'bid_amount': 2.0117618771650174e-05}, {'id': 54450, 'reason': '12', 'creative_id': 135726, 'bid_amount': 2.4237295484638312e-05}]}, {'type': 'TYPE_LEARNING'}], 'bidType': 4, 'isSecureRequest': True, 'sourceType': 3, 'deviceBrand': 82, 'deviceModel': 1, 'sellerNetworkId': 12814, 'interstitialRequest': False, 'nativeAdRequest': True, 'native': {'mainImg': [{'w': 0, 'h': 0, 'wmin': 1200, 'hmin': 627}, {'w': 0, 'h': 0, 'wmin': 1200, 'hmin': 627}, {'w': 0, 'h': 0, 'wmin': 1200, 'hmin': 627}, {'w': 0, 'h': 0, 'wmin': 1200, 'hmin': 627}], 'iconImg': [{'w': 0, 'h': 0, 'wmin': 0, 'hmin': 0}, {'w': 0, 'h': 0, 'wmin': 100, 'hmin': 100}, {'w': 0, 'h': 0, 'wmin': 0, 'hmin': 0}, {'w': 0, 'h': 0, 'wmin': 100, 'hmin': 100}], 'logoImg': [{'w': 0, 'h': 0, 'wmin': 100, 'hmin': 100}, {'w': 0, 'h': 0, 'wmin': 0, 'hmin': 0}, {'w': 0, 'h': 0, 'wmin': 100, 'hmin': 100}, {'w': 0, 'h': 0, 'wmin': 0, 'hmin': 0}]}, 'throttleWeight': 1, 'isSegmentReceived': False, 'viewability': 46, 'bannerAdRequest': False, 'videoAdRequest': False, 'mraidAdRequest': True, 'jsonModelCallCount': 0, 'totalProcessorBids': 1}
这里有人能帮我吗?
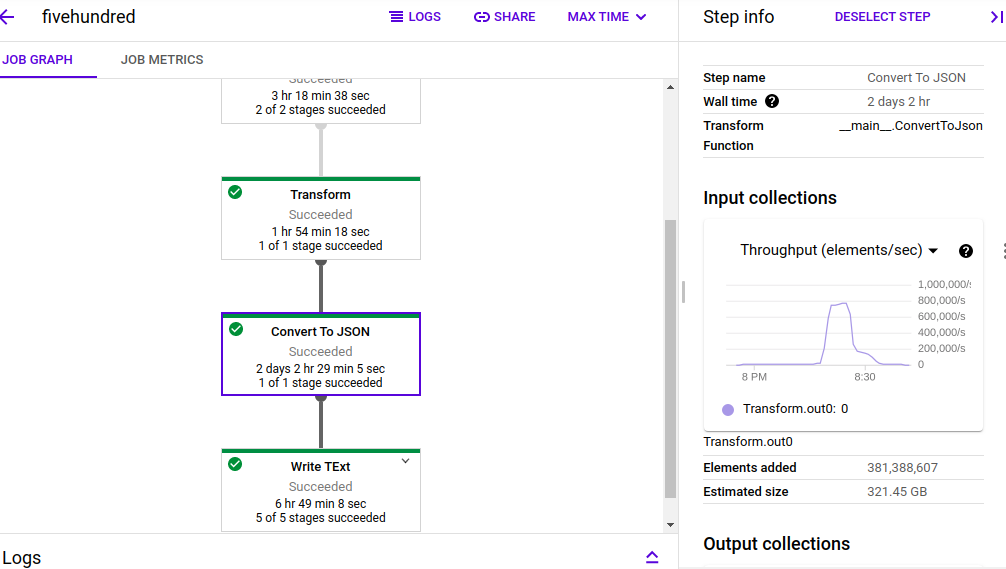
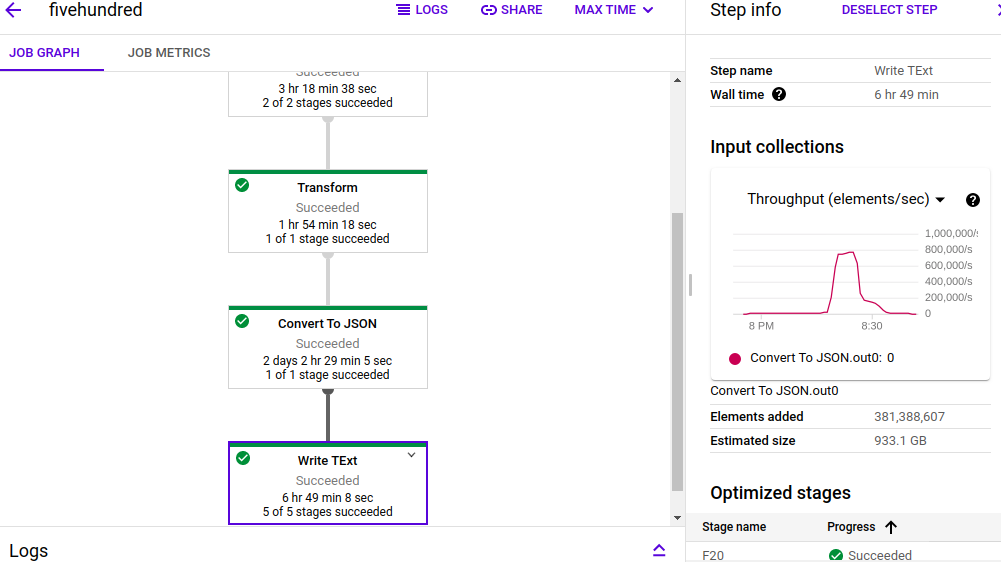
我在这里的建议是使用Java来执行转换。
在Java中,您可以像这样将Modelbuf转换为Avro:使用apache光束在镶木地板中编写Protrabuf对象
完成后,您可以使用AvroIO将数据写入文件。
Java比Python的性能好得多,并且可以节省计算资源。由于这项工作非常简单,不需要任何特殊的Python库,我强烈建议您尝试使用Java。
如果您还没有检查过,只想让您注意“FlexRS”。这使用可抢占虚拟机(VM)实例,这样您就可以降低成本。
