
我有一个以下格式的数据集,其起始列值范围为2021-01-01到2022-03-13,我的值从2021-01-01到2022-03-13开始的结束列也是如此。
每天收集降雨量数据,输入如下:
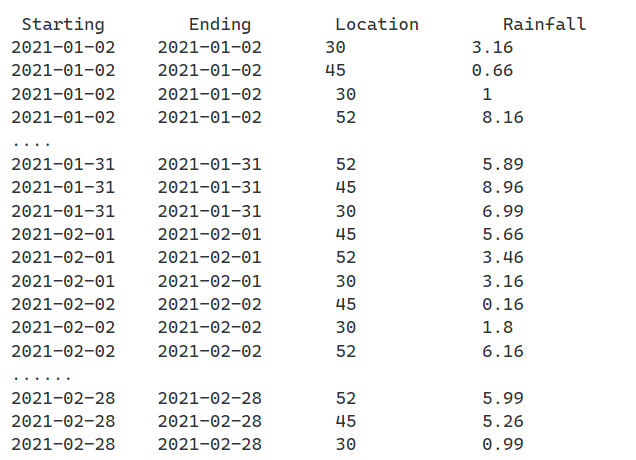
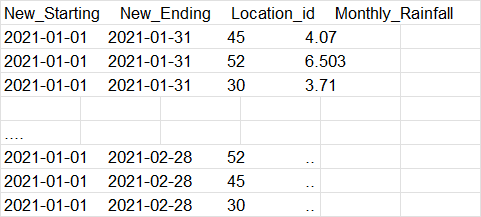
我正在尝试组合和形成数据集的月平均值。我找不到一种方法可以获取月平均值并将它们存储在不同的熊猫数据框中,使其显示如下:
每月降雨量使用当月总降雨量/总天数找到
任何帮助将不胜感激!
我试图使用groupy和均值一起从熊猫库找到输出,但它没有出现在我想要的格式。
df=df. group by(['开始','结束','Location_id'])['降雨量'].means().reset_index()
为了解决这个问题,你可以写一个这样的函数:
import math
from datetime import datetime
def to_date(x, y):
lists = zip([datetime.strptime(dt, '%Y-%m-%d').date() for dt in x], [datetime.strptime(dt, '%Y-%m-%d').date() for dt in y])
return [0 if math.isinf((x-y).days) else (x-y).days for x,y in lists]
基本上,这个函数采用两个列表(x, y),并将其中的每个项目转换为date()对象。并返回一个新的列表,其中包含作为天对象的项目。为了您的信息,如果您扣除相同的日期,Python返回一个inf整数,它是无限的。要检查这个,您可以检查该项目是否是一个信息整数,如果是,则返回0否则返回天。
这是我编写的代码片段,由于您没有提供数据集,因此我使用您提供的图像编写:
import pandas as pd
d = {
'New_Starting': ['2021-01-01','2021-01-01','2021-01-01'],
'New_Ending': ['2021-01-31','2021-01-31','2021-01-31'],
'Location_id': [45, 52, 30],
'Rainfall': [4.07, 6.53, 3.71]
}
d = pd.DataFrame(d)
d['Monthly_Rainfall'] = d['Rainfall'] / to_date(d['New_Ending'], d['New_Starting'])
输出:
New_Starting New_Ending Location_id Rainfall Monthly_Rainfall
0 2021-01-01 2021-01-31 45 4.07 0.135667
1 2021-01-01 2021-01-31 52 6.53 0.217667
2 2021-01-01 2021-01-31 30 3.71 0.123667
