
为什么kfp. v2.dsl.Output作为函数参数在没有提供的情况下工作?
我按照创建和运行ML管道与顶点管道!GCP的Jupyter笔记本示例。
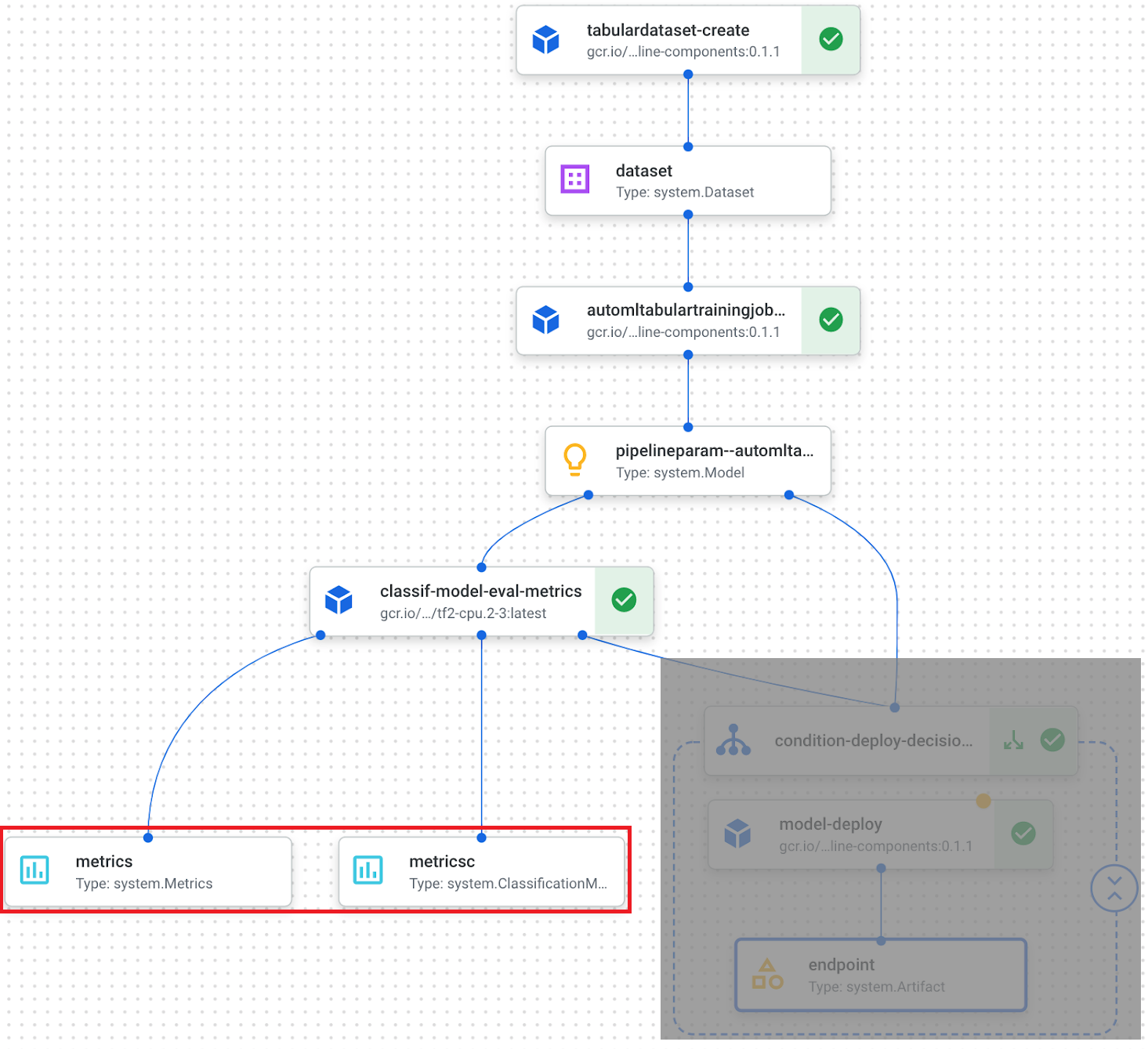
函数classif_model_eval_metrics接受metrics: Output[Metrics]和metricsc:Output[分类度量],它们没有默认值。
@component(
base_image="gcr.io/deeplearning-platform-release/tf2-cpu.2-6:latest",
output_component_file="tables_eval_component.yaml", # Optional: you can use this to load the component later
packages_to_install=["google-cloud-aiplatform"],
)
def classif_model_eval_metrics(
project: str,
location: str, # "us-central1",
api_endpoint: str, # "us-central1-aiplatform.googleapis.com",
thresholds_dict_str: str,
model: Input[Model],
metrics: Output[Metrics], # No default value set, hence must be mandatory
metricsc: Output[ClassificationMetrics], # No default value set, hence must be mandatory
) -> NamedTuple("Outputs", [("dep_decision", str)]):
# Full code at the bottom.
因此,这些参数应该是强制性的,但调用函数时没有这些参数。
model_eval_task = classif_model_eval_metrics(
project,
gcp_region,
api_endpoint,
thresholds_dict_str,
training_op.outputs["model"],
# <--- No arguments for ``metrics: Output[Metrics]``` and ```metricsc: Output[ClassificationMetrics]```
)
整个流水线代码如下。
@kfp.dsl.pipeline(name="automl-tab-beans-training-v2",
pipeline_root=PIPELINE_ROOT)
def pipeline(
bq_source: str = "bq://aju-dev-demos.beans.beans1",
display_name: str = DISPLAY_NAME,
project: str = PROJECT_ID,
gcp_region: str = "us-central1",
api_endpoint: str = "us-central1-aiplatform.googleapis.com",
thresholds_dict_str: str = '{"auRoc": 0.95}',
):
dataset_create_op = gcc_aip.TabularDatasetCreateOp(
project=project, display_name=display_name, bq_source=bq_source
)
training_op = gcc_aip.AutoMLTabularTrainingJobRunOp(
project=project,
display_name=display_name,
optimization_prediction_type="classification",
budget_milli_node_hours=1000,
column_transformations=COLUMNS,
dataset=dataset_create_op.outputs["dataset"],
target_column="Class",
)
model_eval_task = classif_model_eval_metrics(
project,
gcp_region,
api_endpoint,
thresholds_dict_str,
training_op.outputs["model"],
# <--- No arguments for ``metrics: Output[Metrics]``` and ```metricsc: Output[ClassificationMetrics]```
)
它为什么工作以及什么是指标:输出[指标]和指标c:输出[分类指标]类型kfp. v2.dsl.Output?
from kfp.v2.dsl import (
Dataset, Model, Output, Input,
OutputPath, ClassificationMetrics, Metrics, component
)
@component(
base_image="gcr.io/deeplearning-platform-release/tf2-cpu.2-6:latest",
output_component_file="tables_eval_component.yaml", # Optional: you can use this to load the component later
packages_to_install=["google-cloud-aiplatform"],
)
def classif_model_eval_metrics(
project: str,
location: str, # "us-central1",
api_endpoint: str, # "us-central1-aiplatform.googleapis.com",
thresholds_dict_str: str,
model: Input[Model],
metrics: Output[Metrics],
metricsc: Output[ClassificationMetrics],
) -> NamedTuple("Outputs", [("dep_decision", str)]): # Return parameter.
"""Renders evaluation metrics for an AutoML Tabular classification model.
Retrieves the classification model evaluation and render the ROC and confusion matrix
for the model. Determine whether the model is sufficiently accurate to deploy.
"""
import json
import logging
from google.cloud import aiplatform
# Fetch model eval info
def get_eval_info(client, model_name):
from google.protobuf.json_format import MessageToDict
response = client.list_model_evaluations(parent=model_name)
metrics_list = []
metrics_string_list = []
for evaluation in response:
metrics = MessageToDict(evaluation._pb.metrics)
metrics_str = json.dumps(metrics)
metrics_list.append(metrics)
metrics_string_list.append(metrics_str)
return (
evaluation.name,
metrics_list,
metrics_string_list,
)
def classification_thresholds_check(metrics_dict, thresholds_dict):
for k, v in thresholds_dict.items():
if k in ["auRoc", "auPrc"]: # higher is better
if metrics_dict[k] < v: # if under threshold, don't deploy
return False
return True
def log_metrics(metrics_list, metricsc):
test_confusion_matrix = metrics_list[0]["confusionMatrix"]
logging.info("rows: %s", test_confusion_matrix["rows"])
# log the ROC curve
fpr = [], tpr = [], thresholds = []
for item in metrics_list[0]["confidenceMetrics"]:
fpr.append(item.get("falsePositiveRate", 0.0))
tpr.append(item.get("recall", 0.0))
thresholds.append(item.get("confidenceThreshold", 0.0))
metricsc.log_roc_curve(fpr, tpr, thresholds)
# log the confusion matrix
annotations = []
for item in test_confusion_matrix["annotationSpecs"]:
annotations.append(item["displayName"])
metricsc.log_confusion_matrix(
annotations,
test_confusion_matrix["rows"],
)
# log textual metrics info as well
for metric in metrics_list[0].keys():
if metric != "confidenceMetrics":
val_string = json.dumps(metrics_list[0][metric])
metrics.log_metric(metric, val_string)
# metrics.metadata["model_type"] = "AutoML Tabular classification"
aiplatform.init(project=project)
client = aiplatform.gapic.ModelServiceClient(client_options={"api_endpoint": api_endpoint})
eval_name, metrics_list, metrics_str_list = get_eval_info(
client, model.uri.replace("aiplatform://v1/", "")
)
log_metrics(metrics_list, metricsc)
thresholds_dict = json.loads(thresholds_dict_str)
return ("true",) if classification_thresholds_check(metrics_list[0], thresholds_dict) else ("false", )
自定义组件定义为带有@kfp. v2.dsl.组件装饰器的Python函数。
@组件装饰器指定三个可选参数:要使用的基本容器映像;要安装的任何包;和编写组件规范的yaml文件。
组件函数classif_model_eval_metrics有一些输入参数。模型参数是输入kfp. v2.dsl.Model工件。
metrics和metricsc这两个函数参数是组件输出,在本例中是Metrics和分类度量类型。它们不是作为输入显式传递给组件步骤,而是自动实例化并可以在组件中使用。
@component(
base_image="gcr.io/deeplearning-platform-release/tf2-cpu.2-3:latest",
output_component_file="tables_eval_component.yaml",
packages_to_install=["google-cloud-aiplatform"],
)
def classif_model_eval_metrics(
project: str,
location: str, # "us-central1",
api_endpoint: str, # "us-central1-aiplatform.googleapis.com",
thresholds_dict_str: str,
model: Input[Model],
metrics: Output[Metrics],
metricsc: Output[ClassificationMetrics],
)
例如,在下面的函数中,我们调用metricsc.log_roc_curve()和metricsc.log_confusion_matrix()在管道UI中呈现这些可视化效果。这些输出参数在组件编译时成为组件输出,可以被其他管道步骤使用。
def log_metrics(metrics_list, metricsc):
...
metricsc.log_roc_curve(fpr, tpr, thresholds)
...
metricsc.log_confusion_matrix(
annotations,
test_confusion_matrix["rows"],
)
有关更多信息,您可以参考此文档。
