
假设我有一个所有列都是因子的数据框:
set.seed(123)
gender <- sample(1:2,12,replace=T)
country <- c('FIN', 'FIN', 'EST', 'NIG','NIG','JAM', 'FIN', 'NIG', 'EST', 'NIG','NIG','JAM','FIN', 'FIN', 'EST', 'NIG','NIG','JAM', 'FIN', 'NIG', 'EST', 'NIG','NIG','JAM')
a <- sample(1:5,24,,replace=T)
b <- sample(1:5,24,,replace=T)
c <- sample(1:5,24,,replace=T)
d <- sample(1:5,24,,replace=T)
# Join the variables to create a data frame
df <- data.frame(gender,country,a,b,c,d)
df <- df %>% mutate_at(c("gender","country","a","b","c","d"), as.factor)
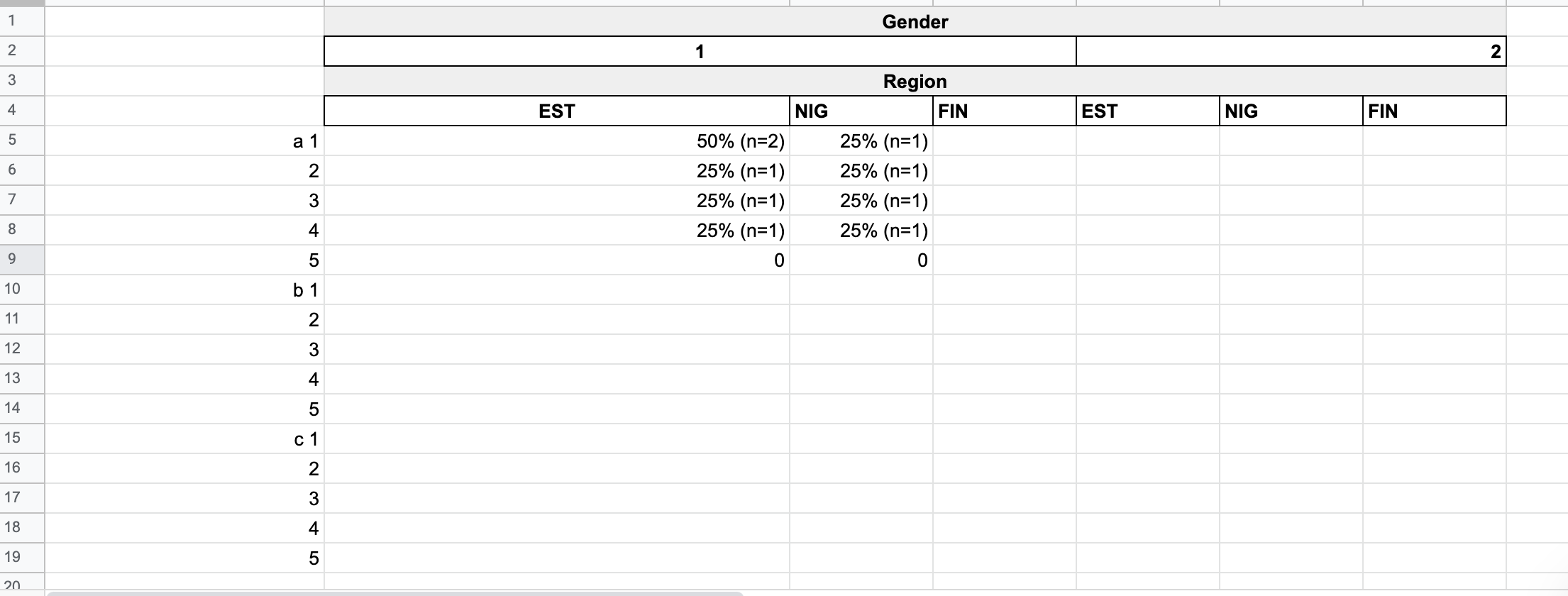
我已经使用代码为a完成了此操作(但我也想为所有其他列b、c、d执行此操作,而不复制代码):
df %>%
group_by(gender,country,a) %>%
summarise(totaln=n()) %>%
group_by(country,gender) %>%
mutate(percentage=totaln/sum(totaln)*100)
所以我得到了这个:
gender country a totaln percentage
<fct> <fct> <fct> <int> <dbl>
1 1 EST 1 2 50
2 1 EST 3 1 25
3 1 EST 4 1 25
4 1 FIN 1 1 25
5 1 FIN 2 3 75
6 1 NIG 1 1 25
7 1 NIG 2 1 25
8 1 NIG 3 1 25
9 1 NIG 4 1 25
10 2 FIN 1 1 50
11 2 FIN 3 1 50
12 2 JAM 1 2 50
13 2 JAM 3 2 50
14 2 NIG 3 1 16.7
15 2 NIG 4 1 16.7
16 2 NIG 5 4 66.7
您可能首先要做的是通过在a: d上使用pivot_longer将数据转换为整齐的格式,然后按此变量分组,从那里它几乎与您编写的代码相同:
df_summary <- df %>% pivot_longer(c(a, b, c, d), names_to = "abcd") %>%
group_by(gender, country, abcd, value) %>%
summarise(totaln = n()) %>%
group_by(country, gender, abcd) %>%
mutate(percentag = totaln / sum(totaln) * 100)
df_summary
#> # A tibble: 64 × 6
#> # Groups: country, gender, abcd [24]
#> gender country abcd value totaln percentag
#> <fct> <fct> <chr> <fct> <int> <dbl>
#> 1 1 EST a 1 1 25
#> 2 1 EST a 3 2 50
#> 3 1 EST a 4 1 25
#> 4 1 EST b 2 1 25
#> 5 1 EST b 3 1 25
#> 6 1 EST b 4 2 50
#> 7 1 EST c 2 1 25
#> 8 1 EST c 5 3 75
#> 9 1 EST d 1 1 25
#> 10 1 EST d 2 2 50
#> # … with 54 more rows
要创建所需的输出形状,您可以执行以下操作:
df_summary %>%
ungroup() %>%
mutate(summary = paste0(round(percentag), "% (n = ", totaln, ")")) %>%
select(gender, country, abcd, value, summary) %>%
pivot_wider(names_from = c(gender, country), values_from = summary, values_fill = "0")
由reprex包(v2.0.1)于2022-06-16创建
两个选项。两者都保留0组合,如果需要,可以轻松地过滤。
>
长格式:
df %>%
tidyr::pivot_longer(-c(gender, country), names_to = "ltr", values_to = "val") %>%
group_by(gender, country, ltr) %>%
summarize(
totaln = sum(as.numeric(table(val))),
percentage = 100 * as.numeric(table(val)) / totaln
) %>%
ungroup()
# `summarise()` has grouped output by 'gender', 'country', 'ltr'. You can override using the `.groups` argument.
# # A tibble: 120 x 5
# gender country ltr totaln percentage
# <fct> <fct> <chr> <dbl> <dbl>
# 1 1 EST a 4 50
# 2 1 EST a 4 0
# 3 1 EST a 4 25
# 4 1 EST a 4 25
# 5 1 EST a 4 0
# 6 1 EST b 4 25
# 7 1 EST b 4 50
# 8 1 EST b 4 25
# 9 1 EST b 4 0
# 10 1 EST b 4 0
# # ... with 110 more rows
宽格式:
df %>%
group_by(gender, country) %>%
summarize(across(a:d,
list(
perc = ~ 100 * as.numeric(table(.)) / sum(as.numeric(table(.))),
total = ~ as.numeric(table(.)),
newval = ~ factor(names(table(.)), levels = levels(.))
)
)) %>%
ungroup()
# `summarise()` has grouped output by 'gender', 'country'. You can override using the `.groups` argument.
# # A tibble: 30 x 14
# gender country a_perc a_total a_newval b_perc b_total b_newval c_perc c_total c_newval d_perc d_total d_newval
# <fct> <fct> <dbl> <dbl> <fct> <dbl> <dbl> <fct> <dbl> <dbl> <fct> <dbl> <dbl> <fct>
# 1 1 EST 50 2 1 25 1 1 75 3 1 0 0 1
# 2 1 EST 0 0 2 50 2 2 0 0 2 50 2 2
# 3 1 EST 25 1 3 25 1 3 0 0 3 25 1 3
# 4 1 EST 25 1 4 0 0 4 0 0 4 25 1 4
# 5 1 EST 0 0 5 0 0 5 25 1 5 0 0 5
# 6 1 FIN 25 1 1 25 1 1 25 1 1 0 0 1
# 7 1 FIN 75 3 2 50 2 2 25 1 2 50 2 2
# 8 1 FIN 0 0 3 0 0 3 25 1 3 25 1 3
# 9 1 FIN 0 0 4 0 0 4 25 1 4 25 1 4
# 10 1 FIN 0 0 5 25 1 5 0 0 5 0 0 5
# # ... with 20 more rows
