
在某些Intel Xeon处理器上运行以下c代码时,我偶然发现了一个特殊的性能问题:
// array_a contains permutation of [0, n - 1]
// array_b and inverse are initialized arrays
for (int i = 0; i < n; ++i) {
array_b[i] = array_a[i];
inverse[array_b[i]] = i;
}
循环的第一行依次将array_a复制到array_b中(预期的缓存未命中次数很少)。第二行计算array_b的倒数(预期的缓存未命中次数很多,因为array_b是一个随机排列)。我们也可以将代码分成两个独立的循环:
for (int i = 0; i < n; ++i)
array_b[i] = array_a[i];
for (int i = 0; i < n; ++i)
inverse[array_b[i]] = i;
我本以为这两个版本(单循环与双循环)在相对现代的硬件上的性能几乎相同。然而,似乎一些至强处理器在执行单循环版本时速度非常慢。
下面你可以看到在一系列不同的处理器上运行代码片段时,以纳米秒为单位的墙时间除以n。为了测试的目的,代码是在具有至强E5-4620v4的系统上使用带有标志-O3-funrol-loops-游行=native的GCC7.5.0编译的。然后,在所有系统上使用相同的二进制文件,在具有多个NUMA域的系统上使用numactl-m 0-N 0。
使用的代码可以在github上找到。有趣的东西在文件runner. cpp中。
[编辑:]此处提供了程序集。
[编辑]新结果包括AMDEPYC。
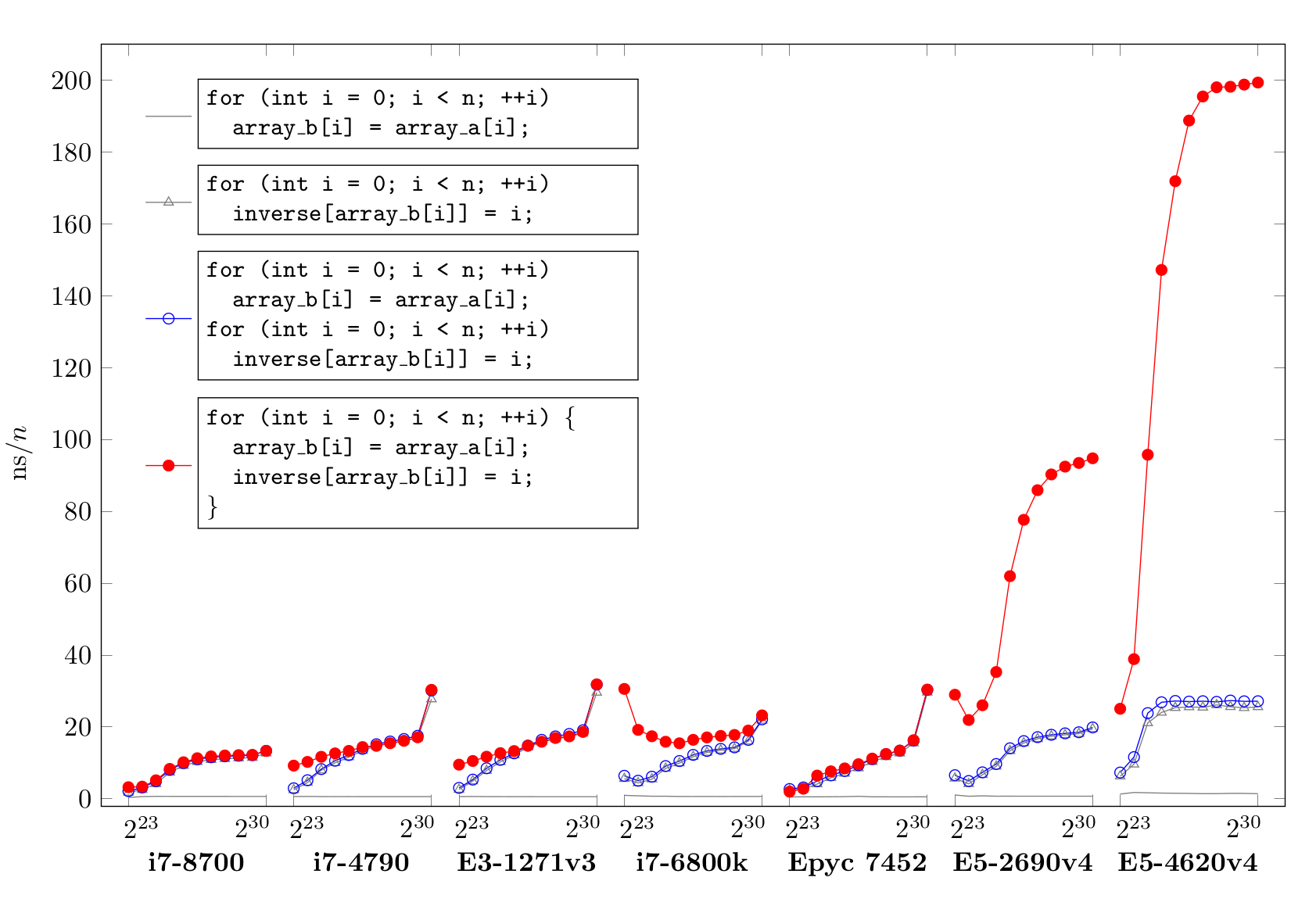
在各种i7机型上,结果大多符合预期。使用单循环仅比双循环稍慢。这也适用于至强E3-1271v3,它与i7-4790的硬件基本相同。AMCEPYC 7452迄今为止表现最好,单循环和双循环实现几乎没有区别。然而,在使用单循环的至强E5-2690v4和E5-4620v4系统上,速度非常慢。
在之前的测试中,我在至强E5-2640和E5-2640v4系统上也观察到了这个奇怪的性能问题。与此相反,在几个AMDEPYC和Opteron系统上没有性能问题,在Intel i5和i7移动处理器上也没有问题。
因此,我对CPU专家的问题是:为什么英特尔最高端的产品线与其他处理器相比表现如此糟糕?到目前为止,我还不是CPU架构的专家,所以非常感谢你的知识和想法!
在玩了下面显示的最小化示例后,我得出的结论是,根本原因是特拉维斯·唐斯2017年问题的一个变体,题为英特尔Skylake上商店循环出乎意料的糟糕和奇怪的双峰性能,为此,他在2019年的博客文章《你的微码最近为你做了什么》中提供了进一步的规范。2020年发给RWT的帖子。我认为问题中显示的图表显示了这种影响是如何在多插座系统上加剧的,在多插座系统中,对RFO的响应需要更长的时间,使得RFO序列化更加明显。
在我的测试程序中,使用PRNG代替带有置换索引的额外数组,效果仍然可见。PRNG有4个周期的延迟,您可以看到,当工作集适合L1缓存时,每次迭代需要的时间比4*多一点(1
#include <stddef.h>
#include <stdio.h>
#include <stdint.h>
#include <sys/mman.h>
static uint64_t prng(int bits)
{
static uint64_t state = 0;
uint64_t ret = state >> (64 - bits);
state = state * 6364136223846793005 + 1;
return ret;
}
typedef uint64_t T;
typedef void fn(volatile T *, int, int);
static void no_prefetch(volatile T *buf, int log_n, int chunk)
{
size_t n = (size_t)1 << log_n;
for (size_t i, k = 0; k < n; k = i) {
for (i = k; i < k + chunk; i++) {
buf[i] = 0;
}
for (i = k; i < k + chunk; i++) {
size_t j = prng(log_n);
buf[j] = 0;
}
}
}
static void do_prefetch(volatile T *buf, int log_n, int chunk)
{
size_t n = (size_t)1 << log_n;
for (size_t i, k = 0; k < n; k = i) {
for (i = k; i < k + chunk; i++) {
buf[i] = 0;
}
for (i = k; i < k + chunk; i++) {
size_t j = prng(log_n);
__builtin_prefetch((T*)buf+j, 1);
buf[j] = 0;
}
}
}
static fn *const fns[] = { no_prefetch, do_prefetch };
int main(int argc, char **argv)
{
unsigned with_prefetch, chunk, log_sz, reps;
if (argc < 2 || sscanf(argv[1], "%u", &with_prefetch) != 1)
with_prefetch = 0;
if (argc < 3 || sscanf(argv[2], "%u", &chunk) != 1)
chunk = 1;
if (argc < 4 || sscanf(argv[3], "%u", &log_sz) != 1)
log_sz = 13;
if (argc < 5 || sscanf(argv[4], "%u", &reps) != 1)
reps = 10000;
size_t sz = sizeof(T) << log_sz;
void *m;
if ((m = mmap(0, sz, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0)) == MAP_FAILED)
return 1;
for (; reps; reps--)
fns[with_prefetch](m, log_sz, chunk);
}
也许这与英特尔处理器上的avx-512频率限制有关。这些指令会产生大量热量,如果在某些情况下使用,处理器会降低工作频率。
以下是一些显示效果的OpenSSL基准测试。Linus Torvalds对此主题进行了咆哮。
如果avx-512指令是使用“-游行=本机”生成的,您可能会受到这种影响。尝试使用以下方法禁用avx-512:
gcc -mno-avx512f
