
我正在使用熊猫分割函数从现有列创建新列。所有这些都很好,我创建了预期的列。问题是它在导出的csv文件中创建了一个额外的列。所以,它说有3列,而实际上有4列。
我尝试了各种函数来删除该列,但它未被识别为数据框的一部分,因此无法成功删除。
希望有人遇到过这个问题,并能提供一个可能的解决方案。
[添加了不必要列的csv数据帧输出示例]
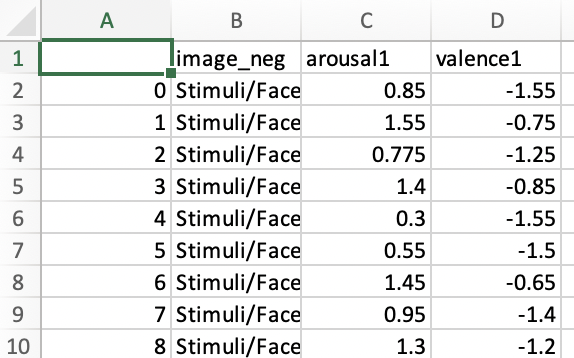
A列不是来自拆分,而是默认情况下实际数据帧的索引。您可以通过在df中设置:index=False来更改它。to_csv
df.to_csv('{PATH}.csv', index=False)
