
我很难理解下面这个方法是如何删除链表中的重复项的。调用这个方法后,所有重复项都被成功删除了。为什么头部不为空?头部节点不会为空,因为方法中的当前变量迭代到最后。这个方法是如何成功更新列表以摆脱重复项的?
static void removeDuplicate(node head)
{
// Hash to store seen values
HashSet<Integer> hs = new HashSet<>();
node current = head;
node prev = null;
while (current != null)
{
int curval = current.val;
// If current value is seen before
if (hs.contains(curval)) {
prev.next = current.next;
} else {
hs.add(curval);
prev = current;
}
current = current.next;
}
}
通过将指针从上一个元素更改为指向下一个元素来删除元素。这就是您通过跳过LinkedList中的元素来删除元素的方式。垃圾收集器稍后将删除该对象,因为不再有对象引用它。
以下是删除的示例:
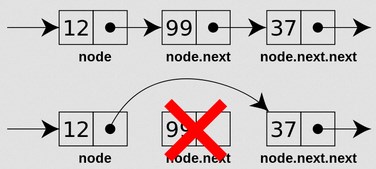
通过记住HashSet中遇到的每个值来识别重复项。如果您找到之前已经遇到的元素(即包含在集合中),则它是重复的。
head无法获取null,因为它之前不是null,并且重复只能发生在第一个元素之后,因为您需要至少遇到一次元素,直到找到重复项。例如,像[1,1,1]这样的列表被修改为[1]而不是[]。
变量head在方法中也没有改变,它指向方法前后的头节点。你似乎被当前=head弄糊涂了,但你需要知道,Java,这不会同步两个变量。如果方法改变了当前,这种改变不会被head反映出来。该语句只是意味着“让当前指向head指向的地方”,然后你让当前指向其他地方。
