
我能够建立到我的Database ricks FileStoreDBFS的连接并访问文件存储。
使用Pyspark读取、写入和转换数据是可能的,但是当我尝试使用本地PythonAPI例如athlib或OS模块时,我无法通过DBFS文件系统的第一级
我可以使用一个神奇的命令:
%fs ls dbfs:\mnt\my_fs\…它完美地工作并列出了所有子目录?
但是如果我做os. listdir('\dbfs\mnt\my_fs\')它返回['挂载.err']作为返回值
我在一个新的集群上测试过这个结果是一样的
我正在使用Python上的数据库运行版本6.1与Apache火花2.4.4
有人能提供建议吗?
连接脚本:
我使用了Database ricksCLI库来存储我的凭据,这些凭据是根据数据库留档格式化的:
def initialise_connection(secrets_func):
configs = secrets_func()
# Check if the mount exists
bMountExists = False
for item in dbutils.fs.ls("/mnt/"):
if str(item.name) == r"WFM/":
bMountExists = True
# drop if exists to refresh credentials
if bMountExists:
dbutils.fs.unmount("/mnt/WFM")
bMountExists = False
# Mount a drive
if not (bMountExists):
dbutils.fs.mount(
source="adl://test.azuredatalakestore.net/WFM",
mount_point="/mnt/WFM",
extra_configs=configs
)
print("Drive mounted")
else:
print("Drive already mounted")
当同一个容器被挂载到工作区中的两个不同路径时,我们遇到了这个问题。卸载所有内容并重新挂载解决了我们的问题。我们使用的是数据库版本6.2(Spark 2.4.4、Scala 2.11)。我们的blob存储容器配置:
运行Notebook脚本以卸载/mnt中的所有挂载:
# Iterate through all mounts and unmount
print('Unmounting all mounts beginning with /mnt/')
dbutils.fs.mounts()
for mount in dbutils.fs.mounts():
if mount.mountPoint.startswith('/mnt/'):
dbutils.fs.unmount(mount.mountPoint)
# Re-list all mount points
print('Re-listing all mounts')
dbutils.fs.mounts()
假设您有一个单独的进程来创建挂载。创建作业定义(job. json)以在自动化集群上运行Python脚本:
{
"name": "Minimal Job",
"new_cluster": {
"spark_version": "6.2.x-scala2.11",
"spark_conf": {},
"node_type_id": "Standard_F8s",
"driver_node_type_id": "Standard_F8s",
"num_workers": 2,
"enable_elastic_disk": true,
"spark_env_vars": {
"PYSPARK_PYTHON": "/databricks/python3/bin/python3"
}
},
"timeout_seconds": 14400,
"max_retries": 0,
"spark_python_task": {
"python_file": "dbfs:/minimal/job.py"
}
}
Python文件(job.py)打印挂载:
import os
path_mounts = '/dbfs/mnt/'
print(f"Listing contents of {path_mounts}:")
print(os.listdir(path_mounts))
path_mount = path_mounts + 'YOURCONTAINERNAME'
print(f"Listing contents of {path_mount }:")
print(os.listdir(path_mount))
运行数据库CLI命令来运行作业。查看Spark Driver输出日志,确认mont. err不存在。
databricks fs mkdirs dbfs:/minimal
databricks fs cp job.py dbfs:/minimal/job.py --overwrite
databricks jobs create --json-file job.json
databricks jobs run-now --job-id <JOBID FROM LAST COMMAND>
我们在连接到Azure Generation2存储帐户(没有分层名称空间)时遇到了同样的问题。
将数据库运行时环境从5.5切换到6. x时似乎会发生错误。但是,我们无法确定确切的原因。我们假设某些功能可能已被弃用。
更新答案:使用Azure Data Lake Gen1存储帐户:dbutils可以访问adls gen1令牌/访问令牌,因此mnt point中的文件列表可以在std py api调用无法访问令牌/火花conf的情况下工作,您看到的第一个调用是列出文件夹,并且它不会对adls api进行任何调用。
我已经在Database ricks Runtime版本6.1中进行了测试(包括Apache Spark 2.4.4、Scala 2.11)
命令正常工作,没有任何错误消息。
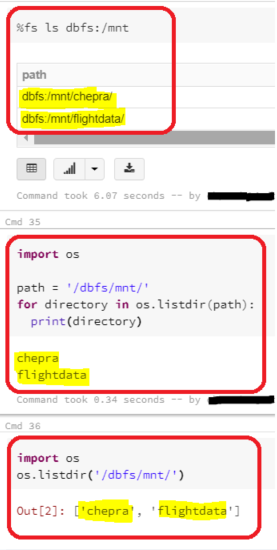
更新:内部文件夹的输出。

希望这有帮助。你能试着让我们知道吗?
