
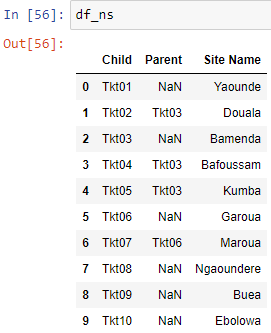
我想计算子列中的值出现在父列中的次数,然后在重命名为子列的新列中显示此计数。 见下面的预览df。
我已经通过VBA(COUNTIFS)完成了这一点,但现在需要动态可视化和动画显示从DIR提供的数据。 所以我求助于Python和Pandas,在搜索和阅读答案后尝试下面的代码,例如:Countif in Pandas with multiple conditions确定value is in Pandas列,迭代Pandas中的行,以及其他许多行。 但仍然无法获得预期的预览,如下图所示。
任何帮助都将不胜感激。 提前谢谢你。
#import libraries
import pandas as pd
import numpy as np
import os
#get datasets
path_dataset = r'D:\Auto'
df_ns = pd.read_csv(os.path.join(path_dataset, 'Scripts', 'data.csv'), index_col = False, encoding = 'ISO-8859-1', engine = 'python')
#preview dataframe
df_ns
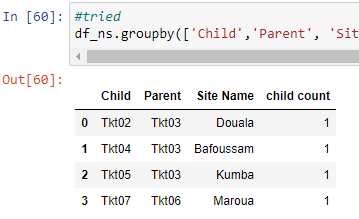
#tried
df_ns.groupby(['Child','Parent', 'Site Name']).size().reset_index(name='child count')
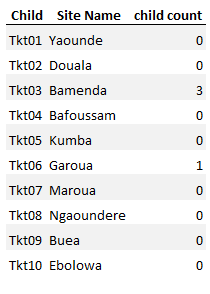
#preview output
df_ns.groupby(['Child','Parent', 'Site Name']).size().reset_index(name='child count')
[已编辑}我的数据
孩子,父母,站点名称'TKT01','','Yaounde''TKT02','','TKT03','Douala''TKT03','','Bamenda''TKT04','','TKT03','Bafoussam''TKT05','','TKT03','Kumba''TKT05','','Garoua''TKT07','','TKT06','Maroua''TKT08','','Ngaoundere''TKT09','','Buea''TKT10','',
由于我没有访问你的数据,我无法检查我给你的代码。 我建议您在使用这一行时会遇到nan值的问题,但您可以尝试一下。:
df_ns['child_count'] = df_ns['Parent'].groupby(df_ns['Child']).value_counts()
我给新列命名,并通过groupby->直接给它赋值; value_counts函数。
