
目前,我正在使用spark structured streaming以(id、时间戳值、设备id、温度值、注释)的形式创建随机数据的数据帧。
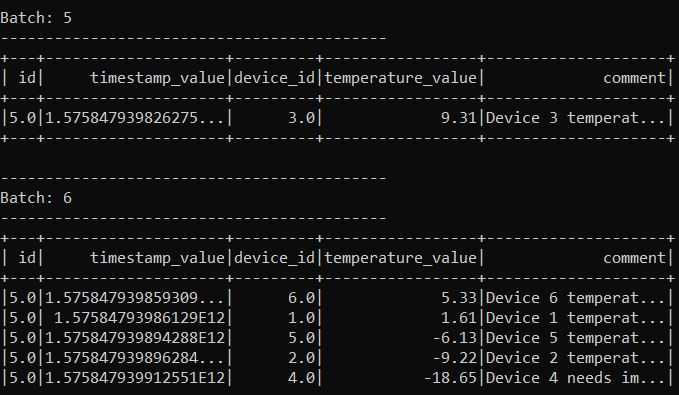
基于上面的数据框截图,我想对“temperature_value”一栏有一些描述性的统计。例如,最小,最大,平均值,计数,方差。
我用python实现这一点的方法如下:
import sys
import json
import psycopg2
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
from pyspark.sql.functions import from_json, col, to_json
from pyspark.sql.types import *
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
from pyspark.sql.functions import get_json_object
from pyspark.ml.stat import Summarizer
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.feature import StandardScaler
from pyspark.sql.functions import lit,unix_timestamp
from pyspark.sql import functions as F
import numpy as np
from pyspark.mllib.stat import Statistics
spark = SparkSession.builder.appName(<spark_application_name>).getOrCreate()
spark.sparkContext.setLogLevel("WARN")
spark.streams.active
data = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "kafka_broker:<port_number>").option("subscribe", <topic_name>).option("startingOffsets", "latest").load()
schema = StructType([
StructField("id", DoubleType()),
StructField("timestamp_value", DoubleType()),
StructField("device_id", DoubleType()),
StructField("temperature_value", DoubleType()),
StructField("comment", StringType())])
telemetry_dataframe = data.selectExpr("CAST(value AS STRING)").select(from_json(col("value").cast("string"), schema).alias("tmp")).select("tmp.*")
telemetry_dataframe.printSchema()
temperature_value_selection = telemetry_dataframe.select("temperature_value")
temperature_value_selection_new = temperature_value_selection.withColumn("device_temperature", temperature_value_selection["temperature_value"].cast(DecimalType()))
temperature_value_selection_new.printSchema()
assembler = VectorAssembler(
inputCols=["device_temperature"], outputCol="temperatures"
)
assembled = assembler.transform(temperature_value_selection_new)
assembled_new = assembled.withColumn("timestamp", F.current_timestamp())
assembled_new.printSchema()
# scaler = StandardScaler(inputCol="temperatures", outputCol="scaledTemperatures", withStd=True, withMean=False).fit(assembled)
# scaled = scaler.transform(assembled)
summarizer = Summarizer.metrics("max", "min", "variance", "mean", "count")
descriptive_table_one = assembled_new.withWatermark("timestamp", "4 minutes").select(summarizer.summary(assembled_new.temperatures))
#descriptive_table_one = assembled_new.withWatermark("timestamp", "4 minutes").groupBy(F.col("timestamp")).agg(max(F.col('timestamp')).alias("timestamp")).orderBy('timestamp', ascending=False).select(summarizer.summary(assembled.temperatures))
#descriptive_table_one = assembled_new.select(summarizer.summary(assembled.temperatures))
# descriptive_table_two = temperature_value_selection_new.select(summarizer.summary(temperature_value_selection_new.device_temperature))
# -------------------------------------------------------------------------------------
#########################################
# QUERIES #
#########################################
query_1 = telemetry_dataframe.writeStream.outputMode("append").format("console").trigger(processingTime = "5 seconds").start()#.awaitTermination()
query_2 = temperature_value_selection_new.writeStream.outputMode("append").format("console").trigger(processingTime = "8 seconds").start()#.awaitTermination()
query_3= assembled_new.writeStream.outputMode("append").format("console").trigger(processingTime = "11 seconds").start()#.awaitTermination()
#query_4_1 = descriptive_table_one.writeStream.outputMode("complete").format("console").trigger(processingTime = "14 seconds").start()#.awaitTermination()
query_4_2 = descriptive_table_one.writeStream.outputMode("append").format("console").trigger(processingTime = "17 seconds").start()#.awaitTermination()
摘要留档。
基于发布的代码,我隔离列temperature_value,然后将其矢量化(使用VectorAssembler)以创建类型向量的列温度。
我想要的是将“摘要器”功能的结果输出到我的控制台。这就是为什么我对outputMode使用“append”并格式化为“console”。但我犯了一个错误:Pypark。sql。乌提尔斯。AnalysisException:“当流数据帧/数据集上存在不带水印的流聚合时,不支持追加输出模式。”。因此,我使用了“withWatermark”函数,但在outputMode“append”中仍然得到相同的错误。
当我试图将输出模式更改为“完成”时,我的终端立即终止了火花流。
即时流媒体终止:
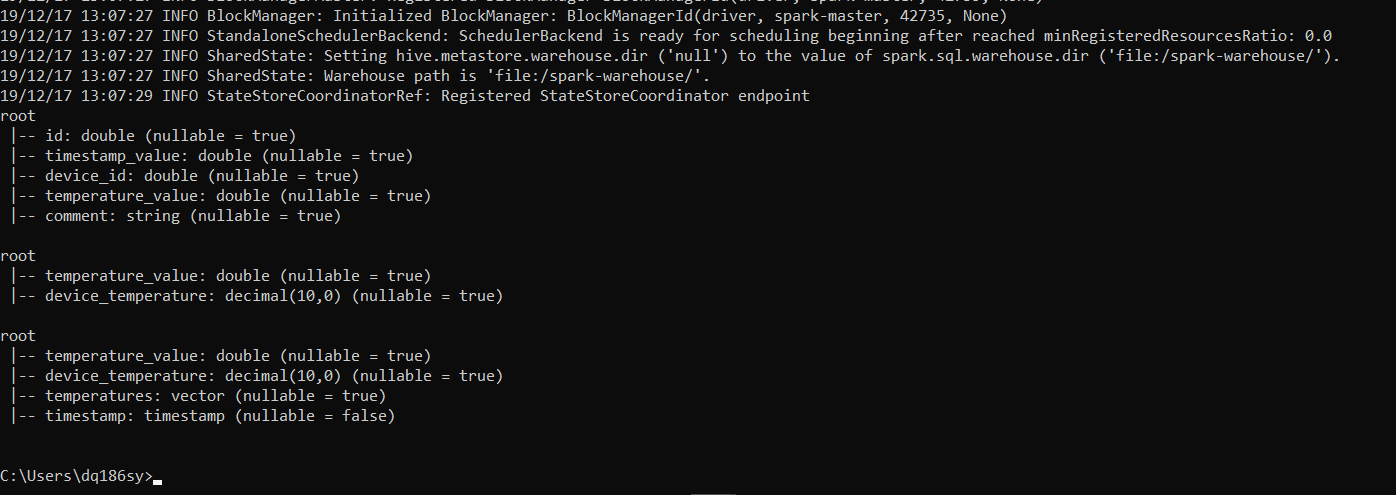
我的问题是:
>
是否有其他方法来计算我的数据框的自定义列的描述性统计数据,我可能会错过?
我感谢你事先的帮助。
编辑(20.12.2019)
解决方案已经给出并被接受。虽然,现在我得到以下错误:


当我试图将输出模式更改为“完成”时,我的终端立即终止了火花流。
您的所有流式查询都已启动并正在运行,但是(pyspark应用程序的主线程)甚至没有给它们长时间运行的机会(因为它不会等待由于#.awaitTermination()而导致的任何终止)。
您应该使用StreamingQuery来阻止pyspark应用程序的主线程。等待终止(),例如查询1。等待终止()
