
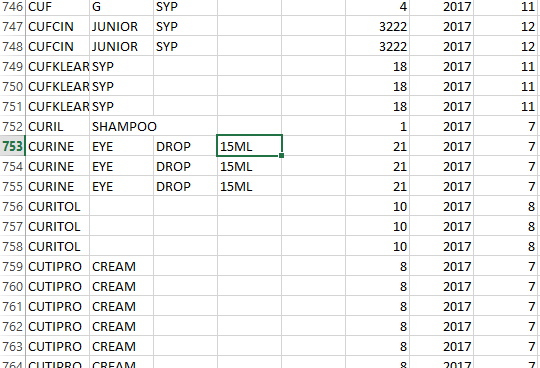
当我用来运行这个代码时,我有这个错误。我尝试过用别人的方法来解决它,但他们并不复杂。数据集如下所示:
我的代码是:
from sklearn.ensemble import RandomForestRegressor
regressor = RandomForestRegressor(n_estimators = 10, random_state = 0)
regressor.fit(df_train, y_train)
错误跟踪:
文件“C:\Users\Acer 15\Anaconda3\lib\site packages\sklearn\utils\validation.py”,第433行,在check\u array array=np中。数组(数组,dtype=dtype,order=order,copy=copy)值错误:无法将字符串转换为浮点:“15ML”
将熊猫数据框中的15ML替换为15,
df['Quantity'].replace('15ML','15')
我假设15ML列的列名是Quantity。应该用实际的列名替换。如果您想按位置访问,您也可以使用
df.ix[:,4].replace('15ML','15')
我已经计算了包括图像中的索引列。实际位置可能会根据您加载数据的方式而有所不同。
