
问题设置:我有一个不平衡的数据集,其中98%的数据属于A类,2%的数据属于B类。我培训了一名决策树分类员(来自sklearn),将class_权重设置为与以下设置平衡:
dtc_settings = {
'criterion': 'entropy',
'min_samples_split': 100,
'min_samples_leaf': 100,
'max_features': 'auto',
'max_depth': 5,
'class_weight': 'balanced'
}
我没有理由将标准设定为熵(而不是基尼)。我只是在玩设置。
我使用tree的export_graphviz得到下面的决策树图。以下是我使用的代码:
dot_data = tree.export_graphviz(dtc, out_file=None, feature_names=feature_col, proportion=False)
graph = pydot.graph_from_dot_data(dot_data)
graph.write_pdf("test.pdf")
我对下面图表中的值列表输出感到困惑:

值列表变量是否意味着两个类的权重相等?如果是,如何计算树中后续节点的值列表?
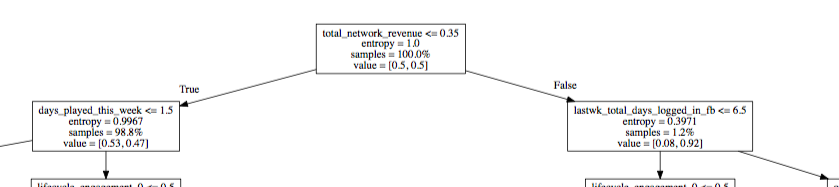
我不知道如何解释价值清单。参赛作品的重量是多少?这是否意味着分类器将这些权重分别应用于每个类,以确定下一个节点中使用的下一个阈值?
该列表表示每个类中已到达该节点的记录数。根据目标变量的组织方式,第一个值表示到达该节点的A类型记录数,第二个值表示到达该节点的B类型记录数(反之亦然)。
当“比例”设置为True时,它现在是每个类到达该节点的记录的分数。
决策树的工作方式是,它试图找到最能隔离类的决策。因此,它更喜欢导致类似[01100]的决策,而不是导致[50,50]
