
我对Keras中的LSTM实现有一些问题。
我的培训集结构如下:
我不确定如何为有状态LSTM塑造输入。
遵循本教程:http://philipperemy.github.io/keras-stateful-lstm/,我已经创建了子序列(在我的情况下,有1452018个window_size=30的子序列)。
重塑有状态LSTM输入数据的最佳选项是什么?
在这种情况下,输入的时间步长是什么意思?为什么?
batch_size与时间步长有关吗?
我不确定如何为有状态LSTM塑造输入。
LSTM(100, statefull=True)
但是在使用有状态的LSTM之前,问问自己我真的需要statefullLSTM吗?有关更多详细信息,请参见此处和此处。
重塑有状态LSTM输入数据的最佳选项是什么?
这真的取决于手头的问题。但是,我认为您不需要重塑,只需将数据直接输入到KERA:
input_layer = Input(shape=(300, 54))
在这种情况下,输入的时间步长是什么意思?为什么?
在您的示例中,时间戳是300。有关时间戳的更多详细信息,请参阅此处。在下面的图片中,我们有5个时间戳,我们将它们输入LSTM网络。
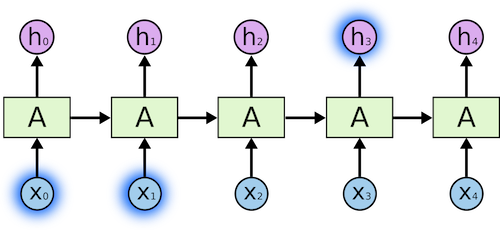
batch_size与时间步长有关吗?
不,这与batch_size无关。关于batch_size的更多细节可以在这里找到。
下面是基于您提供的描述的简单代码。它可能会给你一些直觉:
import numpy as np
from tensorflow.python.keras import Input, Model
from tensorflow.python.keras.layers import LSTM
from tensorflow.python.layers.core import Dense
x_train = np.zeros(shape=(5358, 300, 54))
y_train = np.zeros(shape=(5358, 1))
input_layer = Input(shape=(300, 54))
lstm = LSTM(100)(input_layer)
dense1 = Dense(20, activation='relu')(lstm)
dense2 = Dense(1, activation='sigmoid')(dense1)
model = Model(inputs=input_layer, ouputs=dense2)
model.compile("adam", loss='binary_crossentropy')
model.fit(x_train, y_train, batch_size=512)
