
我很好奇当用于回归时,Graphviz生成的决策树的节点中的value字段是什么。我知道这是使用决策树分类时每个类中被分割的样本数,但我不确定它对回归意味着什么。
我的数据有2维输入和10维输出。下面是一个关于我的回归问题的树的示例:
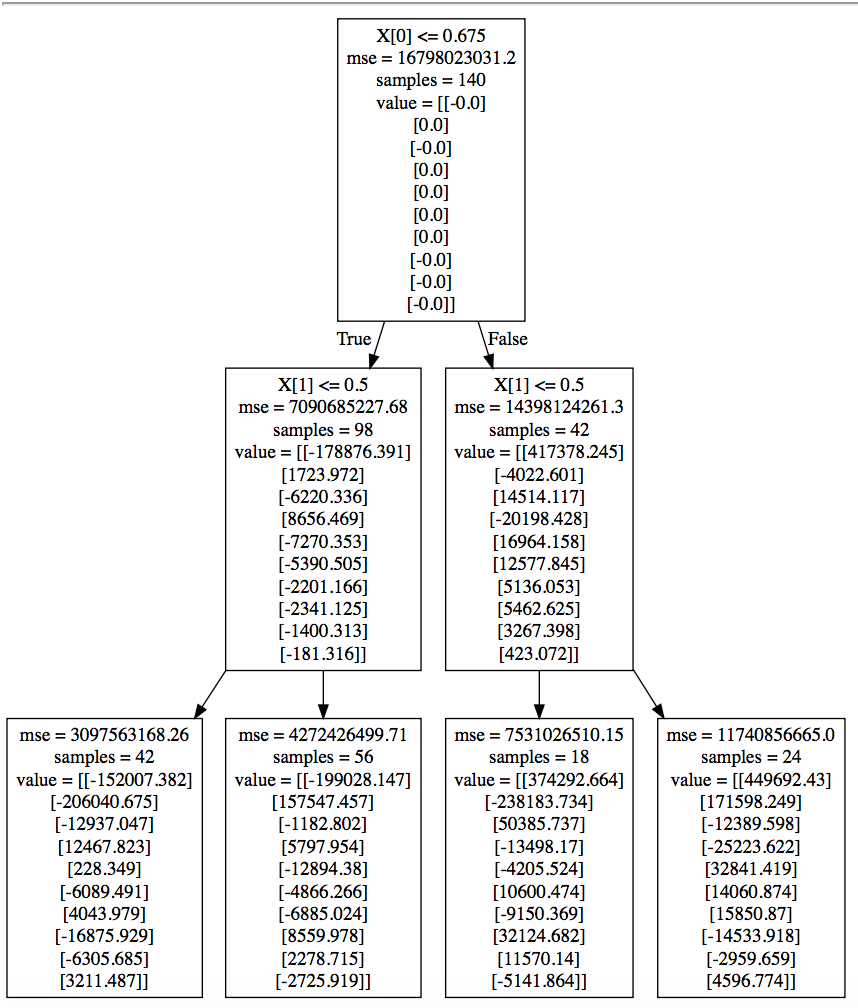
使用此代码制作
# X = (n x 2) Y = (n x 10) X_test = (m x 2)
input_scaler = pickle.load(open("../input_scaler.sav","rb"))
reg = DecisionTreeRegressor(criterion = 'mse', max_depth = 2)
reg.fit(X,Y)
pred = reg.predict(X_test)
with open("classifier.txt", "w") as f:
f = tree.export_graphviz(reg, out_file=f)
回归树作为输出实际返回的是在各个终端节点(叶)中结束的训练样本的因变量(这里是Y)的平均值;这些平均值在图片中显示为名为value的列表,这里的长度都是10,因为Y是10维的。
换句话说,并使用树的最左侧终端节点(叶)作为示例:
X[0]您可以通过预测一些样本(来自您的训练或测试集-这无关紧要)并检查您的10维结果是否是上面描述的4个值列表中的一个来确认情况。
此外,您可以确认,对于value中的每个元素,子节点的加权平均值等于父节点的相应元素。同样,使用2个最左侧终端节点(叶子)的第一个元素,我们得到:
(-42*152007.382 - 56*199028.147)/98
# -178876.39057142858
即它们的父节点(中间级中最左边的节点)的值[0]元素。再举一个例子,这次是2个中间节点的第一个value元素:
(-98*178876.391 + 42*417378.245)/140
# -0.00020000000617333822
这也与根节点的-0.0第一个value元素一致。
从根节点的value列表判断,似乎10维Y的所有元素的平均值几乎为零,您可以(也应该)手动验证,作为最终确认。
因此,总结一下:
value列表包含属于相应节点的训练样本的平均Y值value列表包含整个训练数据集的平均Y值