
我运行YoloV3模型并获得检测结果-包含3个条目的字典:
我知道字典中的每个条目都是其他大小的对象检测。Conv_22用于小型对象Conv_14用于中型对象Conv_6用于大型对象
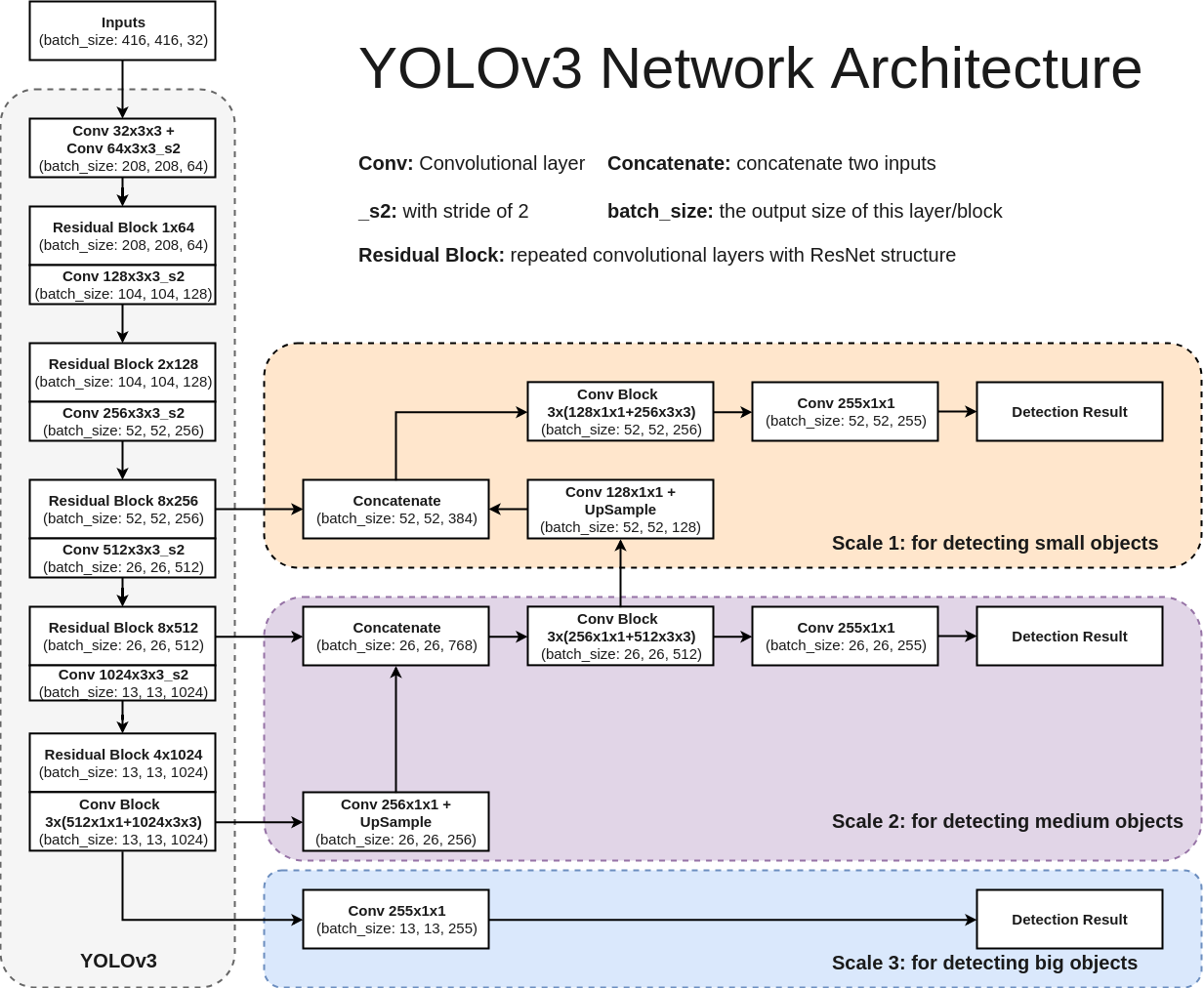
如何将此字典输出转换为边界框、标签和置信度的坐标?
假设您使用python和opencv,
在需要的地方找到下面带有注释的代码,使用cv2.dnn模块提取输出。
net.setInput(blob)
layerOutputs = net.forward(ln)
boxes = []
confidences = []
classIDs = []
for output in layerOutputs:
# loop over each of the detections
for detection in output:
# extract the class ID and confidence (i.e., probability) of
# the current object detection
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
# filter out weak predictions by ensuring the detected
# probability is greater than the minimum probability
if confidence > threshold:
# scale the bounding box coordinates back relative to the
# size of the image, keeping in mind that YOLO actually
# returns the center (x, y)-coordinates of the bounding
# box followed by the boxes' width and height
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# use the center (x, y)-coordinates to derive the top and
# and left corner of the bounding box
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# update our list of bounding box coordinates, confidences,
# and class IDs
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
idxs = cv2.dnn.NMSBoxes(boxes, confidences, confidence, threshold)
#results are stored in idxs,boxes,confidences,classIDs
