
我正在尝试使用BeautifulSoup解析Xtremepapers中的PDF文件:
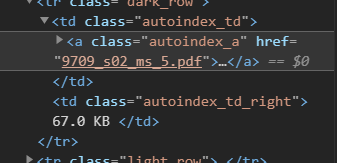
但是,锚标记中的href属性包含指向该特定PDF的下载页面的某种超链接,而不是直接下载链接。
我想要帮助解压下载链接,并通过一些Python脚本保存到我的硬盘驱动器。
好吧,我在这方面还是个新手,所以可能会有些颠簸。 但看起来您使用的是inspect元素,而不是开发人员工具。
如果您使用开发人员工具,点击刷新到网站,然后单击数学名称,您将看到真正的HTML。 你可以看到每个pdf都是这样链接的:
a_tag = <a class="autoindex_a" href="9709_2007_syllabus.pdf">
<img width="16" height="16" alt="[pdf]" src="/images/icons/pdf.png" />
9709_2007_syllabus.pdf </a>
end_url = a_tag.get('href', None)
print(end_url)
>>9709_2007_syllabus.pdf
则只需将该位附加到网站的url“https://papers.xtremepape.rs/caie/as%20 and%20a%20level/mathomethy%20(9709)/”
full_url = 'https://papers.xtremepape.rs/CAIE/AS%20and%20A%20Level/Mathematics%20(9709)/' + end_url
print(full_url) >>https://papers.xtremepape.rs/CAIE/AS%20and%20A%20Level/Mathematics%20(9709)/9709_2007_syllabus.pdf
因此,您以以下链接结束,该链接将您带到thd pdf:https://papers.xtremepape.rs/caie/as%20 and%20a%20level/mathomethy%20(9709)/9709_2007_syllabus.pdf
