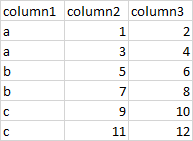
我有一个输入csv文件,如下所示
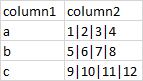
输出应该是这样的
如何利用熊猫实现这一目标?
试试这个,
( pd.melt(df, id_vars="column_1", value_vars=['column_2', 'column_3'], value_name='column_2') .astype(str) .groupby("column_1")['column_2'] .apply(lambda x: "|".join(x)) )