
我试着把所有instagram帖子的赞和用户名保存到txt文件中。
但我发现了一个错误。 此外,我还登录Facebook。
下面是我试过的。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
username = "username"
password = "password"
class Instagram:
def __init__(self,username,password):
self.browserProfile = webdriver.ChromeOptions()
self.browserProfile.add_experimental_option('prefs', {'intl.accept_languages':'en,en_US'})
self.browser = webdriver.Chrome('driverpath//chromedriver.exe', chrome_options=self.browserProfile)
self.username = username
self.password = password
def signIn(self):
self.browser.get("https://www.instagram.com/accounts/login/")
self.browser.maximize_window()
time.sleep(3)
self.browser.find_element_by_xpath('//*[@id="react-root"]/section/main/div/article/div/div[1]/div/form/div[6]/button').click()
usernameInput = self.browser.find_element_by_name('email')
usernameInput.send_keys(self.username)
passwordInput = self.browser.find_element_by_name('pass')
passwordInput.send_keys(self.password)
passwordInput.send_keys(Keys.ENTER)
time.sleep(5)
def getFollowers(self, max):
self.browser.get('https://www.instagram.com/p/CB-Dj1fgZpD/')
time.sleep(5)
self.browser.find_element_by_xpath('//*[@id="react-root"]/section/main/div/div/article/div[3]/section[2]/div/div/button').click()
time.sleep(5)
dialog = self.browser.find_element_by_css_selector("div[role=dialog] div")
users = dialog.find_element_by_css_selector("div")
followerCount = len(users.find_elements_by_css_selector("div"))
print(f"first count: {followerCount}")
action = webdriver.ActionChains(self.browser)
while followerCount < max:
dialog.click()
action.key_down(Keys.SPACE).key_up(Keys.SPACE).perform()
time.sleep(2)
newCount = len(dialog.find_elements_by_css_selector("div"))
if followerCount != newCount:
followerCount = newCount
print(f"second count: {newCount}")
time.sleep(1)
else:
break
followers = users.find_elements_by_css_selector("div")
followerList = []
i = 0
for user in followers:
time.sleep(5)
link = user.find_element_by_css_selector("a").get_attribute("href") #error here.
followerList.append(link)
print(link)
print(followerList)
i += 1
if i == max:
break
with open("followers.txt", "w",encoding="UTF-8") as file:
for item in followerList:
file.write(item + "\n")
instgrm = Instagram(username, password)
instgrm.signIn()
instgrm.getFollowers(100)
我的错误是
找不到css选择器选择器(“a”).get_attribute(“href”)
我不能接受用户名或他们的href(链接)
让我上传一些图片,这样你可以更清楚地了解我在做什么。 有一个包含11个用户的列表。 在这里面,那些类。。。
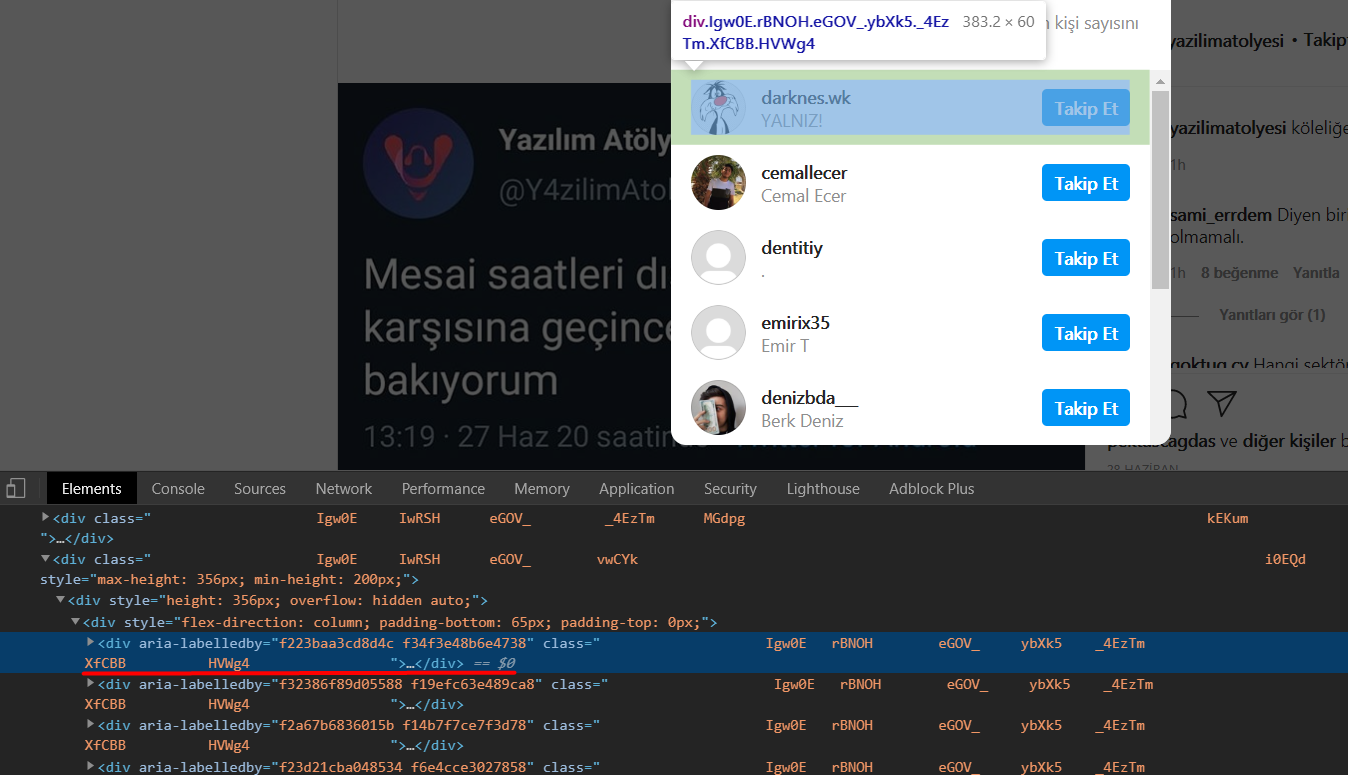
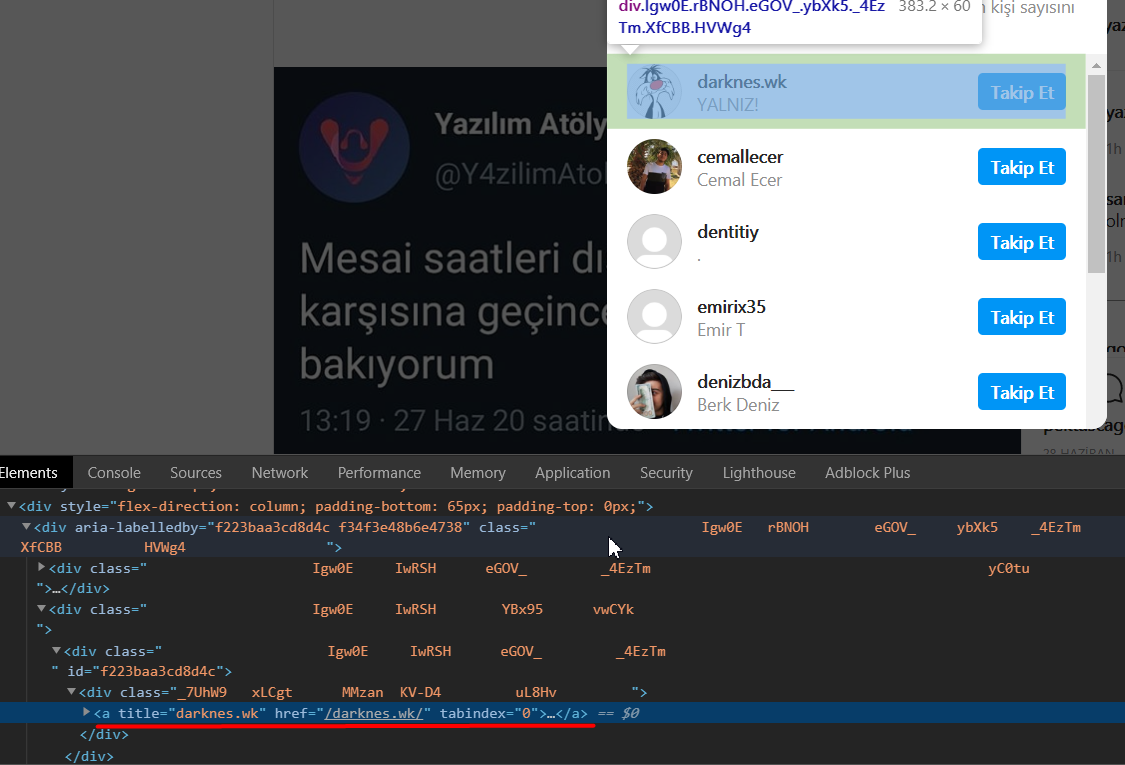
那么,在这种情况下,可以到达title或href变量吗? 谢谢你的帮助。。 快乐编码:)
我建议您使用Instapy,因为它会使您的代码更短,而且我强烈认为它甚至可以轻松地解决您的问题。 以下是文档的链接:https://pypi.org/project/instapy/0.1.0/。
下面是另一个链接,它将向您展示如何制作一个简单的Instagram机器人:
https://realpython.com/instagram-bot-python-instapy/
我希望这能解决你的问题:)
