
我有以下数据
Year <- c("2021","2021","2021","2021","2021","2021")
Month <- c("8","8","8","8","8","8")
Day <- c("10","15","18","20","22","25")
Hour <- c("171110","171138","174247","183542","190156","190236")
Id_Type <- c("2","2","1","","1","")
Code_Intersecction <- c("340","","","210","750","980")
Data = data.frame(Year,Month,Day,Hour,Id_Type,Code_Intersecction)
我需要计算存在于基数中的""的数量,因此我使用以下方法,如果它大于5%,则取1的值,否则为0
Data_Null = as.data.frame(purrr::map_dbl(Data, .f = function(x){ifelse(round(sum(x == '')/nrow(Data)*100L,3) >= 5, 1, 0)}))
colnames(Data_Null) = "Null"
当我看到数据帧时,问题就来了,它只需要一列而不是2;名称和值0/1

我怎样才能使它显示如下
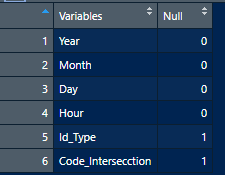
我们可以在base R中的逻辑矩阵上使用colMeans,将命名向量转换为带有堆栈的两列data. frame
stack(+(colMeans(Data == "") > 0.05))[2:1]
解释-数据 == ""返回一个逻辑矩阵,colMeans获取每一列的逻辑向量的平均值(这将是TRUE值的百分比(*100)),然后通过与0.05(5%)进行比较转换为逻辑向量。逻辑可以使用()或使用作为. integer转换为二进制。colMeans的输出是一个命名的向量,它保持不变。堆栈将逻辑命名向量转换为两列data.frame。索引([2:1])将重新排序列,即第2列首先出现,然后是第一列。
-输出
ind values
1 Year 0
2 Month 0
3 Day 0
4 Hour 0
5 Id_Type 1
6 Code_Intersecction 1
使用tidyverse,相当于enframe(来自tibble)
library(dplyr)
library(tidyr)
library(purrr)
map(Data, ~ +(round(mean(.x == ""), 3) * 100 >= 5)) %>%
enframe(name = 'Variables') %>%
unnest(value)
# A tibble: 6 × 2
Variables value
<chr> <int>
1 Year 0
2 Month 0
3 Day 0
4 Hour 0
5 Id_Type 1
6 Code_Intersecction 1
使用tibble:rownames_to_column:
tibble::rownames_to_column(Data_Null, var ="Variables")
# A tibble: 6 x 2
Variables Null
<chr> <dbl>
1 Year 0
2 Month 0
3 Day 0
4 Hour 0
5 Id_Type 1
6 Code_Intersecction 1
基础R:
Data$Variables <- rownames(Data)
