
我尝试读取Avro文件,使用Wrangler进行基本转换(删除名称=Ben的记录),并将结果作为JSON文件写入谷歌云存储。Avro文件具有以下模式:
{"type":"记录","name":"etlSchemaBody","field": [ { "type":"string","name":"name" } ] }
牧马人中的转化如下:转化
以下是JSON文件的输出模式
当我运行管道时,它运行成功,JSON文件在云存储中创建。但是JSON输出为空。尝试预览运行时,我收到以下消息:警告消息
为什么gcloud存储中的JSON输出文件是空的?
使用Wrangler进行转换时,GCS的缺省值是format: text和body:string(数据类型);但是,要正确处理Wrangler中的Avro文件,您需要更改它,您需要将格式设置为blob,将正文数据类型设置为bytes,如下所示:
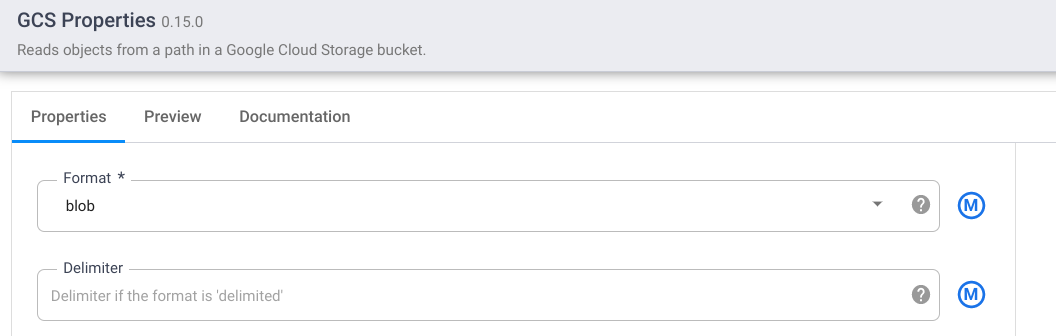
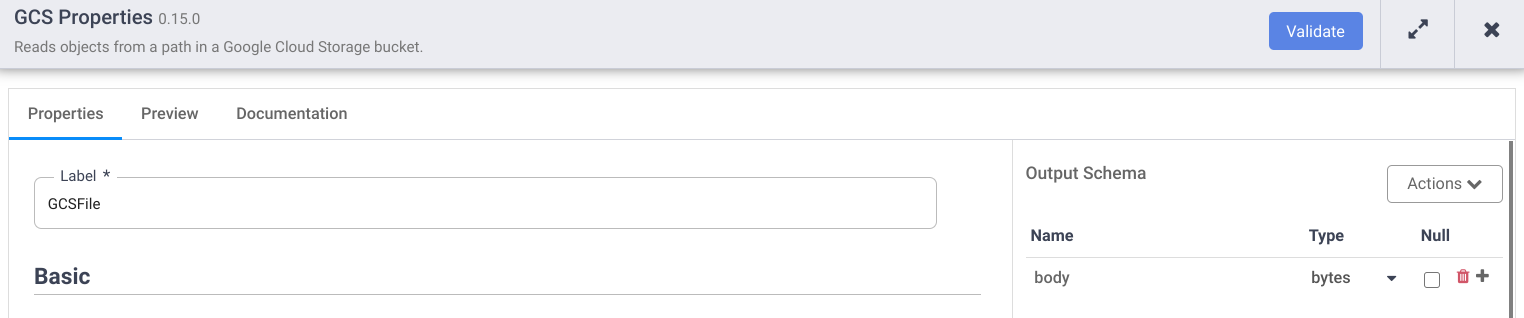
之后,您的管道预览应该会产生输出记录。接下来您可以看到我的工作示例:
编辑:
如果您想在Wrangler中将文件解析为Avro,则需要将格式: blob和输出模式设置为body:bytes,如前所述,因为它需要二进制格式的文件内容。
另一方面,如果您只想应用过滤器(在Wrangler中),您可以执行以下操作:
格式打开文件:avro,见img。name带有string数据类型,请参阅img。这样你也可以得到想要的结果。
