
我有一个解码JWT令牌的代码,拆分包含声明的字符串部分,并将该信息转换为JSON对象。
以LoggedInUser的身份返回JSON. parse(atob(token.split('.')[1]);
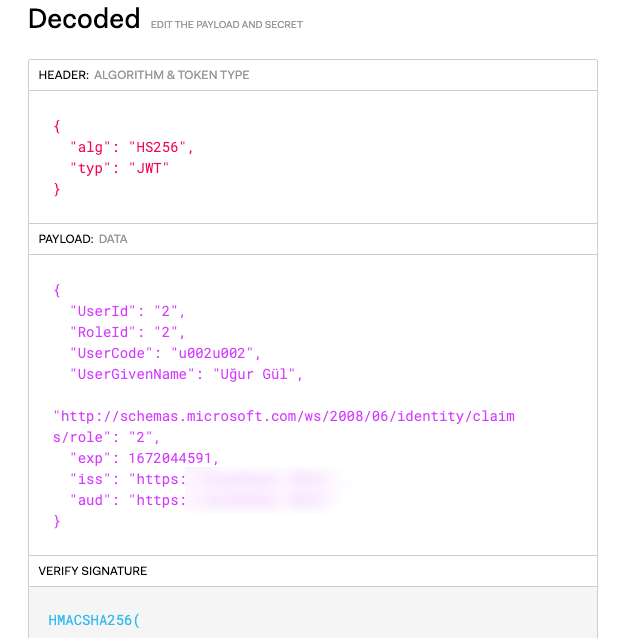
它可以工作,但当涉及到用户名时,由于它有一些土耳其字符,我得到了一个带有不可读字符的字符串。下图中用户名为“Uur Gül”。

我想我应该以某种方式使用utf-8格式解析,但找不到如何解析。我正在使用角框架。我如何解决这个问题?
编辑:这是我在jwt.io上的模拟数据令牌的解码版本。我试图从令牌中获取有效负载,就像jwt.io创建JSON对象的方式一样,我正在将所需的值分配给相关字段到LoggedInUser类的实例。
一种方法是转义和转义后端/前端的名称。我不知道你的应用程序是如何工作的。
样品:
data = '{"UserId":"2","UserGivenName":"U%u011Fur%20G%FCl","http://schemas.microsoft.com/ws/2008/06/identity/claims/role":"2","exp":1672046375,"iss":"https://localhost:7013/","aud":"https://localhost:7013/"}'
constructor() {
console.log((escape("Uğur Gül")));
console.log(unescape(escape("Uğur Gül")))
this.token = (btoa(this.data))
const jsonData = JSON.parse(atob(this.token));
console.log(unescape(jsonData.UserGivenName));
}
转义和un逃逸被标记为已弃用。您可以改用编码URI和解码URI:
console.log(encodeURI('Uğur Gül'));
console.log(decodeURI(encodeURI('Uğur Gül')));
这是一个Stackblitz玩。
