
我正在尝试创建一个Java正则表达式,它将用单个空格替换字符串中所有出现的空格,除非该空格出现在引号之间(单引号或双引号)
如果我只是在寻找双引号,我可以提前看看:
text.replaceAll("\\s+ (?=(?:[^\"]*\"[^\"]*\")*[^\"]*$)", " ");
如果我只是寻找单引号,我可以使用类似的模式。
诀窍是找到两者。
我有一个好主意,运行双引号模式,然后是单引号模式,但当然,这最终会替换所有空格,而不管引号如何。
这里有一些测试和预期结果
a b c d e --> a b c d e
a b "c d" e --> a b "c d" e
a b 'c d' e --> a b 'c d' e
a b "c d' e --> a b "c d' e (Can't mix and match quotes)
有什么方法可以在Java正则表达式中完成此操作吗?
假设已经单独验证了无效输入。因此不会发生以下情况:
a "b c ' d
a 'b " c' d
a 'b c d
它要求结束引号("或')和它后面的字符之间有一个空格才能正确匹配引用的字符串。因此""一些文本不会被这个答案正确处理。
它可能有更多的缺点——但这是一个。
我添加了另一个更优化的答案,它没有错误。
把这个留给后代。
这个支持通过\"和\'和多行引号转义引号。
([^\s"'\\]+)*("[^"\\]*(?:\\.[^"\\]*)*"|'[^'\\]*(?:\\.[^'\\]*)*')*(\s+)
https://regex101.com/r/wT6tU2/1
1美元2美元(是的,最后有一个空格)
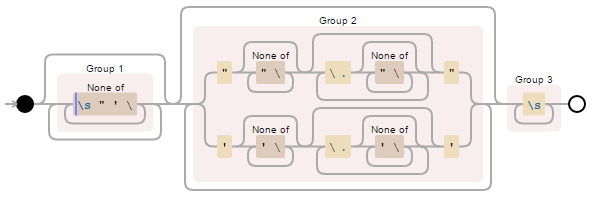
try {
String resultString = subjectString.replaceAll("([^\\s\"'\\\\]+)*(\"[^\"\\\\]*(?:\\\\.[^\"\\\\]*)*\"|'[^'\\\\]*(?:\\\\.[^'\\\\]*)*')*(\\s+)", "$1$2 ");
} catch (PatternSyntaxException ex) {
// Syntax error in the regular expression
} catch (IllegalArgumentException ex) {
// Syntax error in the replacement text (unescaped $ signs?)
} catch (IndexOutOfBoundsException ex) {
// Non-existent backreference used the replacement text
}
// ([^\s"'\\]+)*("[^"\\]*(?:\\.[^"\\]*)*"|'[^'\\]*(?:\\.[^'\\]*)*')*(\s+)
//
// Options: Case sensitive; Exact spacing; Dot doesn’t match line breaks; ^$ don’t match at line breaks; Default line breaks; Regex syntax only
//
// Match the regex below and capture its match into backreference number 1 «([^\s"'\\]+)*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// You repeated the capturing group itself. The group will capture only the last iteration. Put a capturing group around the repeated group to capture all iterations. «*»
// Or, if you don’t want to capture anything, replace the capturing group with a non-capturing group to make your regex more efficient.
// Match any single character NOT present in the list below «[^\s"'\\]+»
// Between one and unlimited times, as many times as possible, giving back as needed (greedy) «+»
// A “whitespace character” (ASCII space, tab, line feed, carriage return, vertical tab, form feed) «\s»
// A single character from the list “"'” «"'»
// The backslash character «\\»
// Match the regex below and capture its match into backreference number 2 «("[^"\\]*(?:\\.[^"\\]*)*"|'[^'\\]*(?:\\.[^'\\]*)*')*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// You repeated the capturing group itself. The group will capture only the last iteration. Put a capturing group around the repeated group to capture all iterations. «*»
// Or, if you don’t want to capture anything, replace the capturing group with a non-capturing group to make your regex more efficient.
// Match this alternative (attempting the next alternative only if this one fails) «"[^"\\]*(?:\\.[^"\\]*)*"»
// Match the character “"” literally «"»
// Match any single character NOT present in the list below «[^"\\]*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// The literal character “"” «"»
// The backslash character «\\»
// Match the regular expression below «(?:\\.[^"\\]*)*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// Match the backslash character «\\»
// Match any single character that is NOT a line break character (line feed, carriage return, next line, line separator, paragraph separator) «.»
// Match any single character NOT present in the list below «[^"\\]*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// The literal character “"” «"»
// The backslash character «\\»
// Match the character “"” literally «"»
// Or match this alternative (the entire group fails if this one fails to match) «'[^'\\]*(?:\\.[^'\\]*)*'»
// Match the character “'” literally «'»
// Match any single character NOT present in the list below «[^'\\]*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// The literal character “'” «'»
// The backslash character «\\»
// Match the regular expression below «(?:\\.[^'\\]*)*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// Match the backslash character «\\»
// Match any single character that is NOT a line break character (line feed, carriage return, next line, line separator, paragraph separator) «.»
// Match any single character NOT present in the list below «[^'\\]*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// The literal character “'” «'»
// The backslash character «\\»
// Match the character “'” literally «'»
// Match the regex below and capture its match into backreference number 3 «(\s+)»
// Match a single character that is a “whitespace character” (ASCII space, tab, line feed, carriage return, vertical tab, form feed) «\s+»
// Between one and unlimited times, as many times as possible, giving back as needed (greedy) «+»
我建议标准化你的字符串封装。使用正则表达式来替换标准的替代。让我们说你解决了双引号“然后你可以拆分你的字符串”,你所有的奇数元素都被引用了内容,你的偶数元素将被取消引用,运行你的正则表达式替换只有偶数元素,并从改变的数组重建你的字符串。
\"和\'和多行引号转义引号。减少步骤数量的几种优化:
\G((?:[^\s"']+| (?!\s)|"[^"\\]*(?:\\.[^"\\]*)*"|'[^'\\]*(?:\\.[^'\\]*)*')*+)(\s+)
https://regex101.com/r/wT6tU2/4
1美元(是的,最后有一个空格)
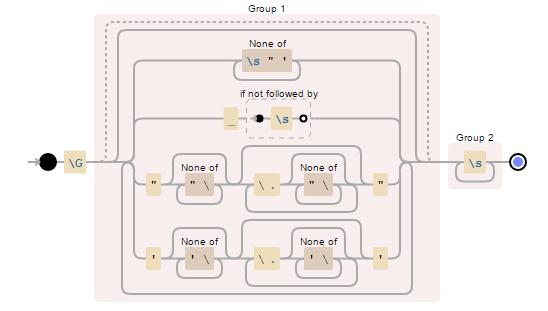
try {
String resultString = subjectString.replaceAll("\\G((?:[^\\s\"']+| (?!\\s)|\"[^\"\\\\]*(?:\\\\.[^\"\\\\]*)*\"|'[^'\\\\]*(?:\\\\.[^'\\\\]*)*')*+)(\\s+)", "$1 ");
} catch (PatternSyntaxException ex) {
// Syntax error in the regular expression
} catch (IllegalArgumentException ex) {
// Syntax error in the replacement text (unescaped $ signs?)
} catch (IndexOutOfBoundsException ex) {
// Non-existent backreference used the replacement text
}
// \G((?:[^\s"']+| (?!\s)|"[^"\\]*(?:\\.[^"\\]*)*"|'[^'\\]*(?:\\.[^'\\]*)*')*+)(\s+)
//
// Options: Case sensitive; Exact spacing; Dot doesn’t match line breaks; ^$ don’t match at line breaks; Default line breaks; Regex syntax only
//
// Assert position at the end of the previous match (the start of the string for the first attempt) «\G»
// Match the regex below and capture its match into backreference number 1 «((?:[^\s"']+| (?!\s)|"[^"\\]*(?:\\.[^"\\]*)*"|'[^'\\]*(?:\\.[^'\\]*)*')*+)»
// Match the regular expression below «(?:[^\s"']+| (?!\s)|"[^"\\]*(?:\\.[^"\\]*)*"|'[^'\\]*(?:\\.[^'\\]*)*')*+»
// Between zero and unlimited times, as many times as possible, without giving back (possessive) «*+»
// Match this alternative (attempting the next alternative only if this one fails) «[^\s"']+»
// Match any single character NOT present in the list below «[^\s"']+»
// Between one and unlimited times, as many times as possible, giving back as needed (greedy) «+»
// A “whitespace character” (ASCII space, tab, line feed, carriage return, vertical tab, form feed) «\s»
// A single character from the list “"'” «"'»
// Or match this alternative (attempting the next alternative only if this one fails) « (?!\s)»
// Match the character “ ” literally « »
// Assert that it is impossible to match the regex below starting at this position (negative lookahead) «(?!\s)»
// Match a single character that is a “whitespace character” (ASCII space, tab, line feed, carriage return, vertical tab, form feed) «\s»
// Or match this alternative (attempting the next alternative only if this one fails) «"[^"\\]*(?:\\.[^"\\]*)*"»
// Match the character “"” literally «"»
// Match any single character NOT present in the list below «[^"\\]*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// The literal character “"” «"»
// The backslash character «\\»
// Match the regular expression below «(?:\\.[^"\\]*)*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// Match the backslash character «\\»
// Match any single character that is NOT a line break character (line feed, carriage return, next line, line separator, paragraph separator) «.»
// Match any single character NOT present in the list below «[^"\\]*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// The literal character “"” «"»
// The backslash character «\\»
// Match the character “"” literally «"»
// Or match this alternative (the entire group fails if this one fails to match) «'[^'\\]*(?:\\.[^'\\]*)*'»
// Match the character “'” literally «'»
// Match any single character NOT present in the list below «[^'\\]*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// The literal character “'” «'»
// The backslash character «\\»
// Match the regular expression below «(?:\\.[^'\\]*)*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// Match the backslash character «\\»
// Match any single character that is NOT a line break character (line feed, carriage return, next line, line separator, paragraph separator) «.»
// Match any single character NOT present in the list below «[^'\\]*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// The literal character “'” «'»
// The backslash character «\\»
// Match the character “'” literally «'»
// Match the regex below and capture its match into backreference number 2 «(\s+)»
// Match a single character that is a “whitespace character” (ASCII space, tab, line feed, carriage return, vertical tab, form feed) «\s+»
// Between one and unlimited times, as many times as possible, giving back as needed (greedy) «+»
