
我正试图绘制GPU的价格与加密货币的价格。
我已经能够创建2个单独的可视化,按年显示GPU的平均价格和加密货币的平均价格,但似乎无法将它们结合起来。
...
plt.plot(GPUDATA.groupby(GPUDATA['Date'].dt.strftime('%Y')['Price_USD'].mean())
...
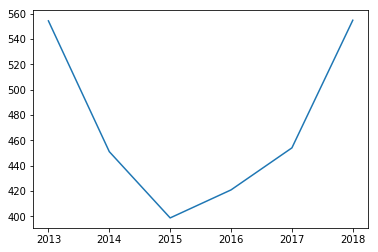
plt.plot(BITCOINDATA.groupby(BITCOINDATA['Date'].dt.strftime('%Y'))['Open'].mean())
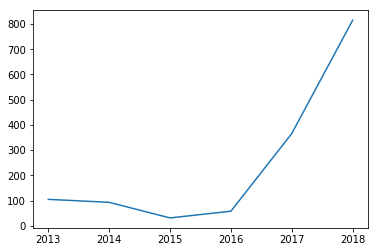
我需要将这两个可视化组合成一个图形。我对创建可视化有点陌生,所以我不确定需要提供多少信息。我很乐意提供更多需要的信息!谢谢!
编辑:数据框中的条目列出了产品的id,然后是日期,然后是该日期的产品价格。正因为如此,GPU数据框和Crypto数据框上都有很多重复的年份和id,这就是我按功能分组的原因。
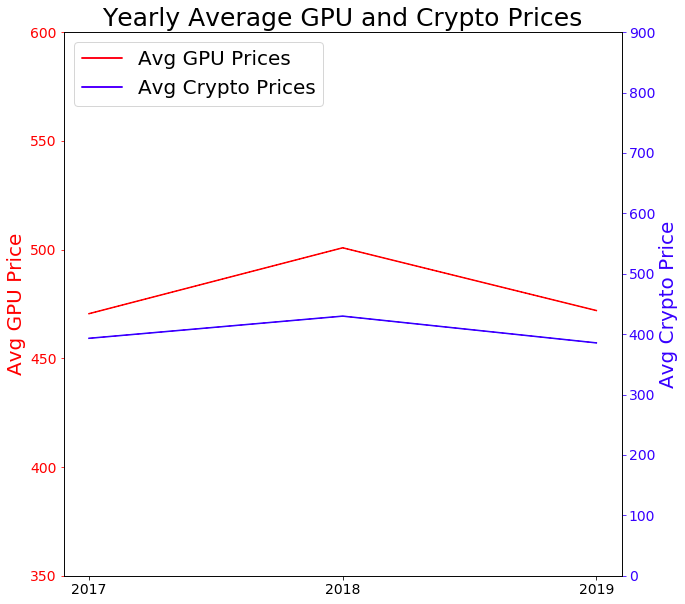
这是一个为每个系列创建单独y轴的解决方案。我生成了随机数据,这就是图表看起来不同的原因。您可以在下面修改每个y轴的下界和上限等参数。
import matplotlib.pyplot as plt
fig, ax1 = plt.subplots(figsize=(10,10))
ax2 = ax1.twinx()
ax1.plot(GPUDATA.groupby(GPUDATA['Date'].dt.strftime('%Y'))['Price_USD'].mean(),'r', label = 'Avg GPU Prices')
ax1.set_ylabel("Avg GPU Price", color='r', fontsize=20)
ax1.set_ylim(350,600)
ax1.tick_params(axis='y', colors= 'r', labelsize=14)
ax1.tick_params(axis='x', colors= 'k', labelsize=14)
ax2.plot(BITCOINDATA.groupby(BITCOINDATA['Date'].dt.strftime('%Y'))['Open'].mean(), 'b', label = 'Avg Crypto Prices')
ax2.set_ylabel("Avg Crypto Price", color='b', fontsize=20)
ax2.set_ylim(0, 900)
ax2.tick_params(axis='y', colors= 'b', labelsize=14)
lines, labels = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax1.legend(lines + lines2, labels + labels2, loc=2, fontsize=20)
ax1.grid(b=False)
ax2.grid(b=False)
plt.title("Yearly Average GPU and Crypto Prices", fontsize=25)
plt.show()
plt.close('all')
ax = GPUDATA.groupby(GPUDATA['Date'])['Price_USD'].mean().plot()
BITCOINDATA.groupby(BITCOINDATA['Date'])['Open'].mean().plot(ax=ax)
plt.show()

您可以使用绘图参数添加标签和图例
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.plot.html
