
我想问你,如果我不使用有状态流,我是否需要在我的KafkaStreamsConfiguration中使用复制因子。我不使用这个RockDB。据我所知,复制因子设置是针对变更日志和重新分区主题的。我理解这个变更日志主题,但是这个重新分区主题有点让我困惑…有人能用非常基本的语言解释一下这个修复主题是什么吗?如果我在流式应用程序中不使用状态,我是否应该关心这个复制因子?
问候
简而言之,当您更改正在处理的事件/消息的键时,Kafka Streams中会发生重新分区。
重新划分基本上是流处理的洗牌阶段。这可能发生在Kafka流、Apache Spark、Flink、Storm、Hadoop中……这些是分布式流处理引擎(DSPE),旨在并行执行任务以加快流程。然后,当您调用map转换时,DSPE将此逻辑map转换为并行度为X的物理map任务(X通常是机器的内核数)。
因此,如果您使用mapValue并且不更改键,Kafka流不会重新分区。但是如果您使用map更改键,Kafka流将重新分区。此外,如果您使用任何聚合转换(例如:duce,join,…)Kafka将执行重新分区,因为它基于键。
重新分区/混洗阶段发生在有聚合阶段时。假设您有一个逻辑管道:
... -
引擎盖下的物理管道将如下所示:
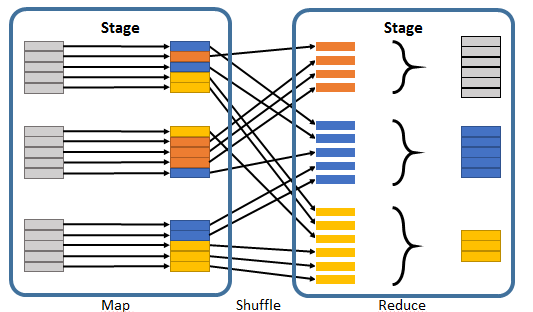
具有相同键的事件由groupByKey转换分组并发送到同一个duce并行任务实例。这是洗牌阶段。
在Kafka流的情况下,当聚合发生时,管道从KStream转换为KTable,因为消息分布在Kafka代理上,流引擎必须查找不同分区上的事件。如果您使用IntelliJ,它会在管道更改时影响您。在下图中,它发生了字数,count转换是有状态的,就像减少一样。
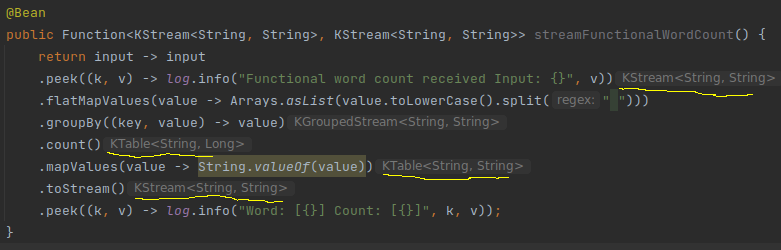
这是一个很好的来源,可以阅读更多关于Kafka Stream中重新分区的信息。就像我说的,其他DSPE在随机播放阶段也依赖于重新分区。其他不错的来源是来自Flink的这个。
