
我正在使用AnyLogic 8.7.9 PLE对基于规则的模拟进行建模。我想将此模拟的结果与Bonsai训练的大脑的结果进行比较。对于基于规则的模拟,我通过参数变化实验运行了100次单个配置。当我想使用训练过的大脑运行相同时,我收到了以下错误:
root. bonsaiConnector:此块仅适用于模拟实验。
我正在考虑解决这个问题的方法,我想从一次实验运行中运行所有内容,我在下面的查询中找到了更多信息:
在任何逻辑中运行N倍的模拟
现在,我的问题是,运行这100个基于规则的模拟大约需要3-5个小时,因为其中一些模拟是并行运行的,有没有一种解决方法,我可以并行运行训练好的大脑刺激的100次运行中的至少一部分,而不是连续运行它们,这样就不会超过基于规则的模拟所需的时间?
免责声明:我没有用盆景脑Rest过,有可能它不适用于自定义实验
警告:前方Java
您可以使用自定义实验功能运行模拟。
下面的示例改编自您可以在此处找到的模拟模型生命周期文章,但增加了多线程的进步。代码可以强加在这个简单的示例上,它会很好地工作。
创建一个自定义实验,并在附加类代码中添加一些自定义代码。理想情况下,在此函数中,您提供一些包含模型所有输入数据的场景类,以及存储模型所有结果数据的结果类。
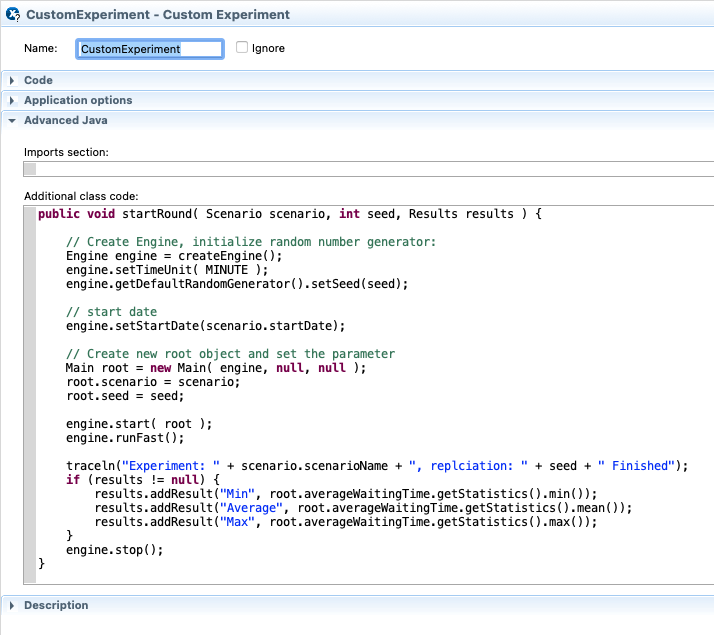
public void startRound( Scenario scenario, int seed, TextFile customerQueueTimeFile, Results results ) {
// Create Engine, initialize random number generator:
Engine engine = createEngine();
engine.setTimeUnit( MINUTE );
engine.getDefaultRandomGenerator().setSeed(seed);
// start date
SimpleDateFormat dateFormatter = new SimpleDateFormat("yyyy-MM-dd");
try {
engine.setStartDate(dateFormatter.parse("2021-02-01"));
} catch (ParseException e) {
throw new AssertionError("Invalid date: ");
}
// Create new root object and set the parameter
Main root = new Main( engine, null, null );
root.scenario = scenario;
root.seed = seed;
root.customerQueueTimeFile = customerQueueTimeFile;
engine.start( root );
engine.runFast();
traceln("Experiment: " + scenario.scenarioName + ", replciation: " + seed + " Finished");
if (results != null) {
results.addResult("Min", root.averageWaitingTime.getStatistics().min());
results.addResult("Average", root.averageWaitingTime.getStatistics().mean());
results.addResult("Max", root.averageWaitingTime.getStatistics().max());
}
engine.stop();
}
如果您想并行运行这些自定义实验,则需要实现多线程。
为此,您可以为要运行的每个复制创建一个新的runnable,然后在runnable中调用函数来运行自定义实验。
当线程池中只有1个活动线程时,您可以保存输出
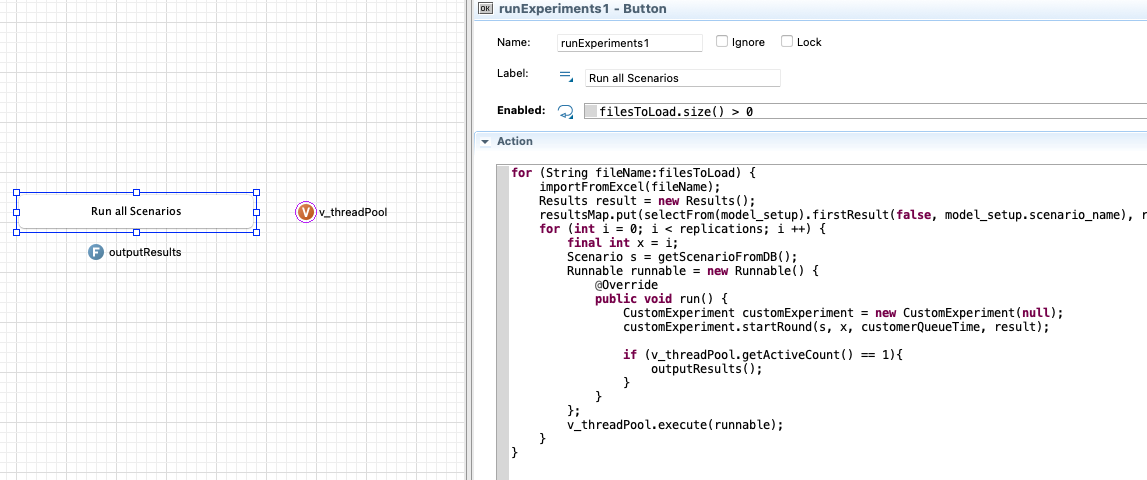
for (String fileName:filesToLoad) {
importFromExcel(fileName);
Results result = new Results();
resultsMap.put(selectFrom(model_setup).firstResult(false, model_setup.scenario_name), result);
for (int i = 0; i < replications; i ++) {
final int x = i;
Scenario s = getScenarioFromDB();
Runnable runnable = new Runnable() {
@Override
public void run() {
CustomExperiment customExperiment = new CustomExperiment(null);
customExperiment.startRound(s, x, customerQueueTime, result);
if (v_threadPool.getActiveCount() == 1){
outputResults();
}
}
};
v_threadPool.execute(runnable);
}
}
v_threadPool只是一个线程池执行器,以确保您不会同时运行太多线程。

