
所以我遇到了一个有趣的问题。我正试图优化我在日本的solr索引,用于日本字符。
本质上的问题是,Solr没有意识到带长标记的单词和不带长标记的单词是同一个单词。我不懂日语,但我和一个懂日语的人一起工作,他们告诉我,当你搜索 ビームエキスパンダー 它会返回结果,这是应该的。
但是如果你搜索 ビームエキスパンダ, 是同一个词,但是减去最后的长标记,它不会返回任何结果。我们被索引的内容都包含 ビームエキスパンダー, 但是我们本质上希望solr包含内容,即使你不搜索长标记来包含有长标记的内容。
这是我们的日本模式看起来像我正在寻找的领域。
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt"/>
<filter class="solr.SynonymGraphFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt" />
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.WordDelimiterGraphFilterFactory" preserveOriginal="1" catenateWords="1"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt"/>
<filter class="solr.SynonymGraphFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.WordDelimiterGraphFilterFactory" preserveOriginal="1" catenateWords="1"/>
</analyzer>
</fieldType>
当我搜索光束扩展器时,没有长标记,这就是它的解析方式。
"querystring":"ビームエキスパンダ",
"parsedquery":"+DisjunctionMaxQuery((((((+CategoryName_txt:ビーム +CategoryName_txt:エキス +CategoryName_txt:パンダ) CategoryName_txt:ビームエキスパンダ))~1)))",
"parsedquery_toString":"+(((((+CategoryName_txt:ビーム +CategoryName_txt:エキス +CategoryName_txt:パンダ) CategoryName_txt:ビームエキスパンダ))~1))",
当我搜索 ビームエキスパンダー 末尾有长标记时,它是这样解析的。
"querystring":"ビームエキスパンダー",
"parsedquery":"+DisjunctionMaxQuery((((CategoryName_txt:ビーム CategoryName_txt:エキスパンダ)~2)))",
"parsedquery_toString":"+(((CategoryName_txt:ビーム CategoryName_txt:エキスパンダ)~2))",
对此的任何帮助都将不胜感激。
-保罗
更新根据要求,我附上了这些术语的solr分析的屏幕截图。
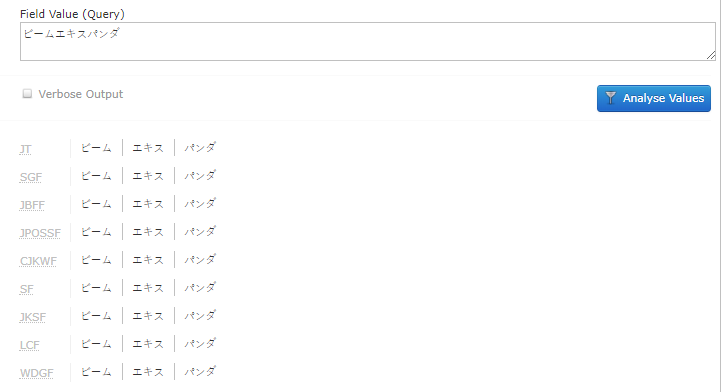
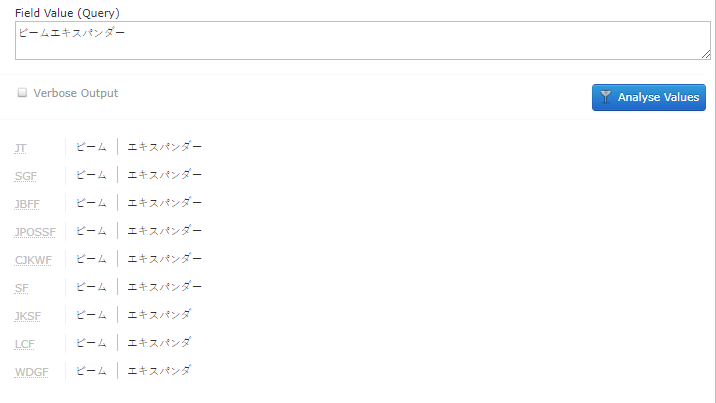
这里出现的术语是光束扩展器。它被用破折号分析,作为光束扩展器,这是完美的。虽然没有破折号,但它被分析为三个独立的单词。
ー是光束。这是正确的。但扩展器正在被分析为术语和,根据谷歌翻译,这意味着提取和熊猫。
我解决了这个问题。我不是日语专家,但从我能看出的关于日语的一件有趣的事情是,他们不使用空格来描述单词的结尾。短语BeamSplitter和日语中的BeamExtractPanda本质上是同一个单词,solr只是想尽最大努力确定单词的分割位置。
这就是用户字典的用武之地。对我来说,这个文件位于默认位置lang/userdict_ja. txt。
我在下面添加了一行。.光束扩展器,光束扩展器,光束扩展器,光束扩展器
我可能错了,但据我所知,这里的第一列应该是被搜索的单词错误,第二和第三列应该是同一个单词,但有一个空格指示它应该被标记器分割的位置。
我相信这样的例子是不寻常的,所以我对此没有意见,宁愿保留日本的TokenizerFactory并放入边缘案例,也不愿使用标准的TokenizerFactory并减少优化。
谢谢大家的帮助。
-保罗
我想知道您是否需要在索引和查询分析器中使用solr. CJKBigram FilterFactory。在普通的Solr 7中,我在text_cjk字段上获得预期结果(即它找到有或没有长标记的匹配项)。见下图:
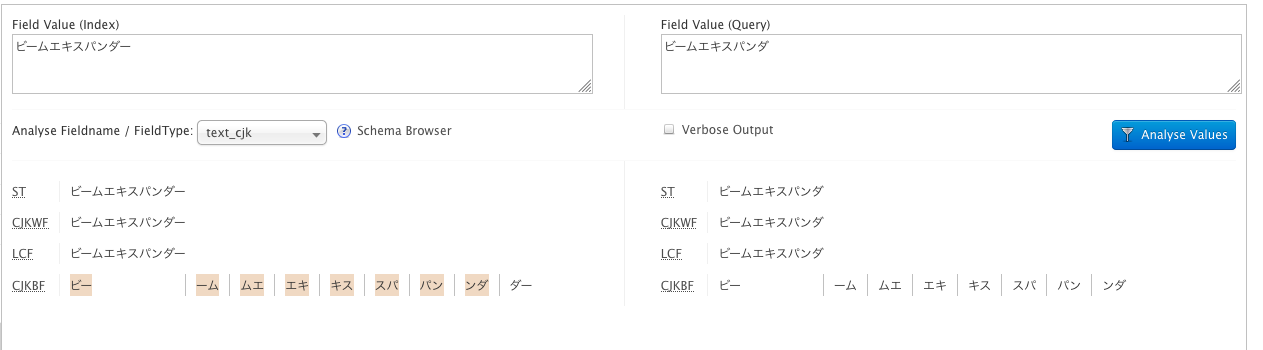
下面是text_cjk字段在Solr中的定义方式:
$ curl http://localhost:8983/solr/cjktest/schema/fieldtypes/text_cjk
{
"responseHeader":{
"status":0,
"QTime":1},
"fieldType":{
"name":"text_cjk",
"class":"solr.TextField",
"positionIncrementGap":"100",
"analyzer":{
"tokenizer":{
"class":"solr.StandardTokenizerFactory"},
"filters":[{
"class":"solr.CJKWidthFilterFactory"},
{
"class":"solr.LowerCaseFilterFactory"},
{
"class":"solr.CJKBigramFilterFactory"}]}}}
