
我有一个简单的密码查询,需要很长时间才能完成。
节点类型
>
个人{个人ID,个人邮箱地址}
文档{DocumentId}
关系类型: SENT,TO,CC,BCC
概念是:
(p:人)-[:发送]-
我试图让那些人,任何给定的人发送最大的邮件。
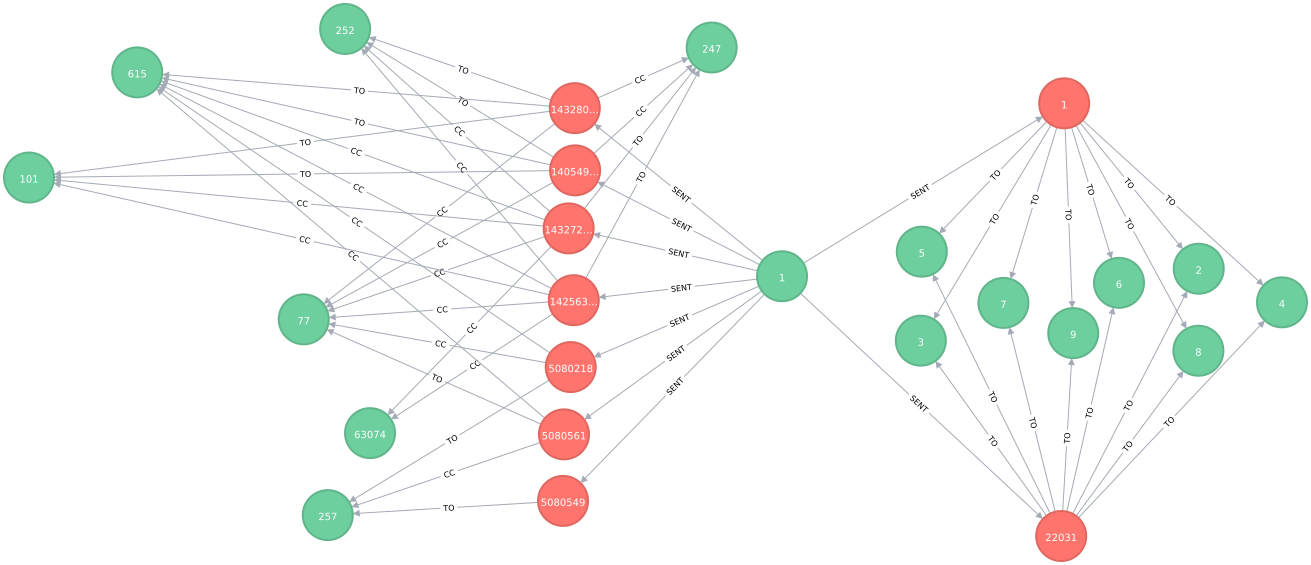
例如,您可以在下图中看到Person#1向Person#77和Person#615发送了最多的邮件(6封邮件),依此类推。所以在这里,我想要(如下表所述)前5个Person id,其中包含发送给该人的邮件数量。
+------------+-----------------------+
| ReceiverId | NumberOfMailsReceived |
+------------+-----------------------+
| 77 | 6 |
| 615 | 6 |
| 101 | 4 |
| 247 | 4 |
| 252 | 4 |
+------------+-----------------------+
我正在尝试以下查询:
MATCH(p:Person{PersonId:1})-->(d) WITH DISTINCT d
MATCH (d)-->(rc)
RETURN rc, COUNT(rc) as c ORDER BY c DESC LIMIT 5
这里此查询没有性能问题,因为Person#1仅发送了9个文档,并且只有15人作为这9个文档的接收者参与其中。
但是,如果我为发送了总计近56,500个文档的不同人员触发相同的查询,并且总共有869个(不同的)人员作为接收者参与,则查询需要43261毫秒才能完成
Cypher version: CYPHER 3.1, planner: COST, runtime: INTERPRETED. 21570218 total db hits in 43261 ms.
简介如下

我的neo4j浏览器在数据库部分下显示Size: 5.16 GiB。
这是我正在使用的配置:
dbms.memory.heap.initial_size=8G
dbms.memory.heap.max_size=8G
dbms.memory.pagecache.size=4g
有什么建议或想法来优化查询?
提前感谢。
编辑
将Neo4j版本从3.1.1更新到3.2后,查询仍然需要大约23368毫秒。
我不认为你可以对你的原始DBHITS做任何事情,因为你的查询已经非常小了(唯一浪费的精力是DISTINCT在示例情况下不过滤任何东西);但是你CAN尝试像这样并行你的查询
MATCH (p:Person{PersonId:1})-->(d)
MATCH (d)-[:TO]->(rc)
WITH d, COLLECT(rc) AS list
MATCH (d)-[:CC]->(rc)
WITH d, list + COLLECT(rc) AS list
MATCH (d)-[:BCC]->(rc)
WITH d, list + COLLECT(rc) AS list
UNWIND list AS rc
RETURN rc, COUNT(rc) as c
ORDER BY c DESC
LIMIT 5
(您可能需要a在某处使用“USING JOIN ON d”以使Cypher并行分解工作)
您应该能够通过文档从源Person遍历到收件人,而不是将文档上的不同作为中间步骤。
此查询如何支持您的数据集?
MATCH(p:Person {PersonId:1})
WITH p
MATCH (p)-->(:Document)-->(rc:Person)
RETURN rc, COUNT(rc) AS c
ORDER BY c DESC
LIMIT 5
