
来自Azure的DocumentDB(Cosmos db)后台到AWS DynamoDB,用于已经使用dynamo db的应用程序。
我对DynamoDB上的分区键感到困惑。
据我所知,分区键用于在数据增长时将数据隔离到不同的分区,但是许多人建议使用主键作为分区键,例如用户ID、客户ID、订单ID。在这种情况下,我不确定我们如何获得更好的性能,因为我们有很多分区。所以一个查询可能需要在多个服务器上执行。
例如,如果我想开发一个多租户系统,在该系统中,我将使用单个表存储所有租户的数据,但使用租户id进行分区。我将按照下面文档db中提到的方法进行操作。
使用以下架构创建对象。
Primary key: Order Id
Partition key: Tenant id
SELECT * FROM Orders o WHERE o.tenantId="tenantId"
SELECT * FROM Orders o WHERE o.Id='id' and o.tenantId="tenantId"
SELECT * FROM Orders o WHERE o.tenantId="tenantId" order by o.CreatedData
//by default all fields in document db are indexed, so order by just works
如何在dynamo db中实现相同的操作?
最后我找到了如何正确使用Dynamodb。感谢[@Jesse Carter],他的评论对更好地理解Dynamo db非常有帮助。我现在正在回答我自己的问题。
与其他NoSQL db的DynamoDB相比,DynamoDB有点困难,因为术语太容易混淆,下面我已经提到了一些常见场景的简化DynamoDB表设计。
在Dynamo db中,主键不需要是唯一的,我知道这与所有其他产品相比非常令人困惑,但这是事实。主键(在dyanmodb中)实际上是“分区键”。
您始终需要在查询中提供主键
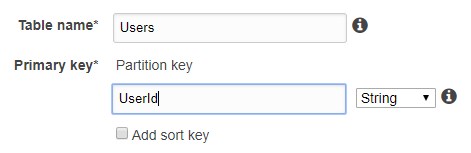
假设您要创建一个包含Id和多个其他属性的表。您还仅基于Id属性进行查询。在这种情况下,Id可以是主键。
|---------------------|------------------|
| User Id | Name |
|---------------------|------------------|
| 12 | value1 |
| 13 | value2 |
|---------------------|------------------|
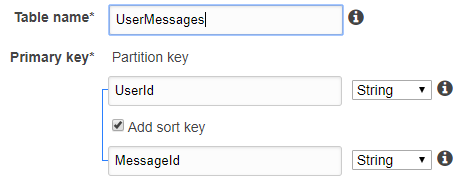
现在,假设我们要按如下所示为用户存储消息,我们将按用户id查询以检索用户的所有消息。
|---------------------|------------------|
| User Id | Message Id |
|---------------------|------------------|
| 12 | M1 |
| 12 | M2 |
| 13 | M3 |
|---------------------|------------------|
“用户Id”仍然是该表的主键。请记住,dynamodb中的主键不需要每个文档都是唯一的。消息Id可以是排序键
排序键是分区中的一种唯一键。分区键和排序键的组合必须是唯一的。
如果您使用的是Visual Studio,则可以安装AWS Visual Studio工具包,以便在计算机上创建本地表进行测试。
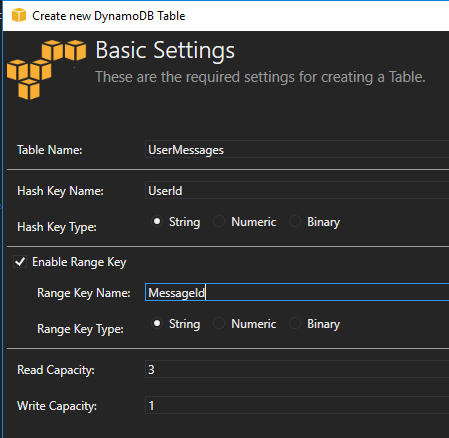
哈希键,范围键。总是让发电机db感到惊讶,不是吗?:)。实际上
(Primary Key = Partition Key = Hash Key) != Your application objects primary key
根据我们的第二个场景,“消息ID”应该是我们应用程序的主键,但是根据DynamoDB术语,用户ID成为实现分区优势的主键。
(Sort key = Range Key) = Could be a application objects primary
我们可以在分区内创建索引,这称为本地二级索引。例如,如果我们希望根据消息状态为用户检索消息
|------------|--------------|------------|
| User Id | Message Id | Status |
|------------|--------------|------------|
| 12 | M1 | 1 |
| 12 | M2 | 0 |
| 13 | M3 | 2 |
|------------|--------------|------------|
主键:用户Id
排序键:消息ID
辅助本地索引:状态
顾名思义,它是一个全局索引。如果我们想要基于id检索单个消息,而不需要分区键,即用户id,那么我们应该基于消息id创建一个全局索引。
请参见AWS文件中的说明,
主键唯一标识表中的每个项。主键可以是简单键(分区键)或复合键(分区键和排序键)。
在存储数据时,DynamoDB将表的项划分为多个分区,并主要根据分区键值分发数据。因此,要实现为表提供的全部请求吞吐量,请将工作负载均匀分布在分区键值上。跨分区分发请求键值跨分区分发请求。
例如,如果一个表有非常少的大量访问的分区键值,甚至可能只有一个使用非常频繁的分区键值,那么请求流量将集中在少数分区上,可能只有一个分区。如果工作负载严重不平衡,这意味着它过度集中在一个或几个分区上,那么请求将无法达到总体配置的吞吐量水平。为了最大限度地利用DynamoDB吞吐量,请创建分区键具有大量不同值的表,并且这些值的请求尽可能均匀、随机。
这并不意味着您必须访问所有分区键值才能达到吞吐量水平;也不意味着访问的分区键值的百分比需要很高。但是,请注意,当您的工作负载访问更多不同的分区键值时,这些请求将以更好地利用分配的吞吐量级别的方式分布在分区空间中。通常,随着访问的分区键值与表中分区键值总数的比率增加,您将更有效地利用吞吐量。
据我所知,分区键用于在数据增长时将数据分隔到不同的分区,但许多人建议使用主键作为分区键,如用户Id、客户Id、订单Id。在这种情况下,我不确定如何实现更好的性能,因为我们有许多分区。
您是正确的,在DynamoDB中使用分区键将数据隔离到不同的分区。但是,项目重新出现的分区键和物理分区不是一对一的映射。
分区的数量取决于您的RCU/WCU,这样所有RCU/WCU都可以被利用。
在dynamo db中,主键不需要唯一。我理解这与其他所有产品相比非常令人困惑,但这是事实。主键(在dynamoDB中)实际上是“分区键”。
这是一种错误的理解。主键的概念与SQL标准完全相同,但有额外的限制,正如您所期望的NoSQL数据库一样。简而言之,您可以将分区键作为主键,也可以将分区键和排序键作为复合主键。
