
tl;博士:“我如何通过一堆异步、无序的微服务推送消息,并知道该消息何时通过每个微服务?”
我正在努力为特定的微服务体系结构找到合适的消息传递系统/协议。这不是一个“哪个是最好的”问题,而是一个关于我的设计模式/协议选项的问题。
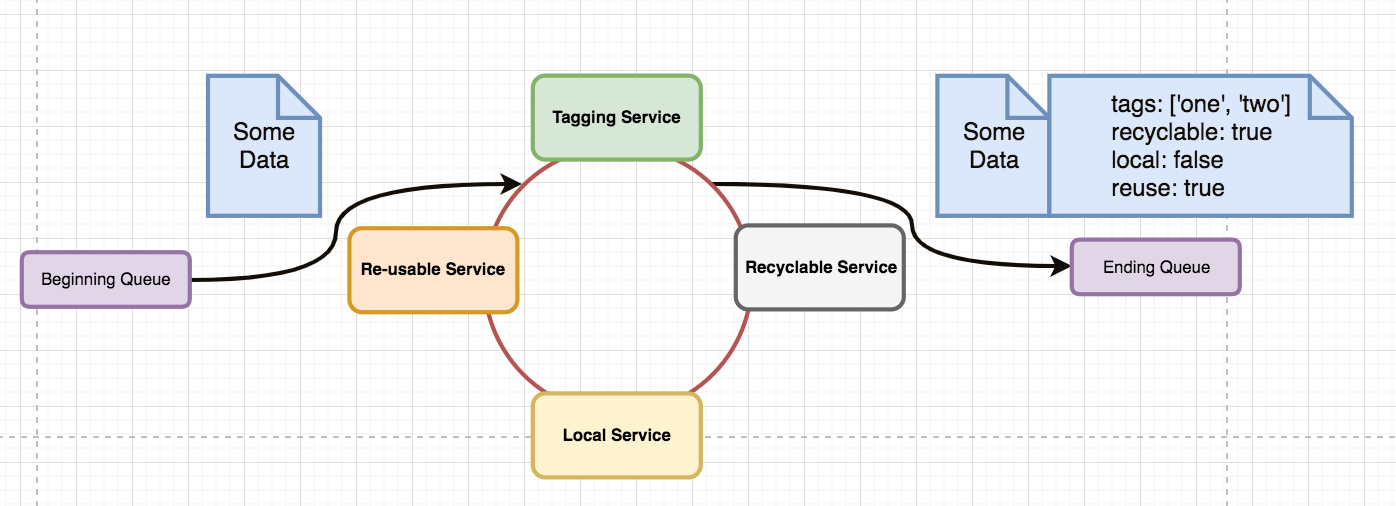
所以,问题是,通过各种服务管理该消息的适当方式是什么?我不想一次做一个,而且顺序也不重要。但是,如果是这样的话,系统如何知道所有服务何时都已完成,并且最终消息可以写入到结束队列中(以便让下一批服务完成)。
我唯一能想到的半优雅的解决方案是
但这仍然要求每个服务都知道所有其他服务,并要求每个服务都留下自己的印记。这两个都不是我们想要的。
我愿意接受某种“牧羊人”服务。
我很感激我错过的任何选择,并愿意承认它们可能是一个更好的基本设计。
非常感谢。
管理长时间运行的流程(或涉及多个微服务的流程)有两种方法:编排和编排。有很多文章描述了它们。
长话短说:在编排中,您有一个跟踪流程状态的微服务,在编排中,所有微服务都知道下一条消息发送到哪里和/或流程何时完成。
本文解释了这两种风格的好处和权衡。
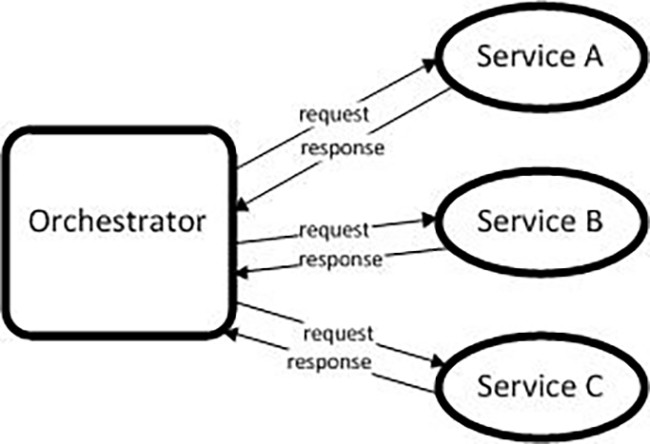
编排优势
业务流程权衡
>
将服务耦合在一起,创建依赖关系。如果服务A关闭,则永远不会调用服务B和C。
如果所有请求都有一个orchestrator的中央共享实例,则orchestrator是一个单点故障。如果下降,所有处理都会停止。
利用阻止请求的同步处理。在此示例中,端到端的总流转时长是调用服务A服务B服务C所需的时间之和。
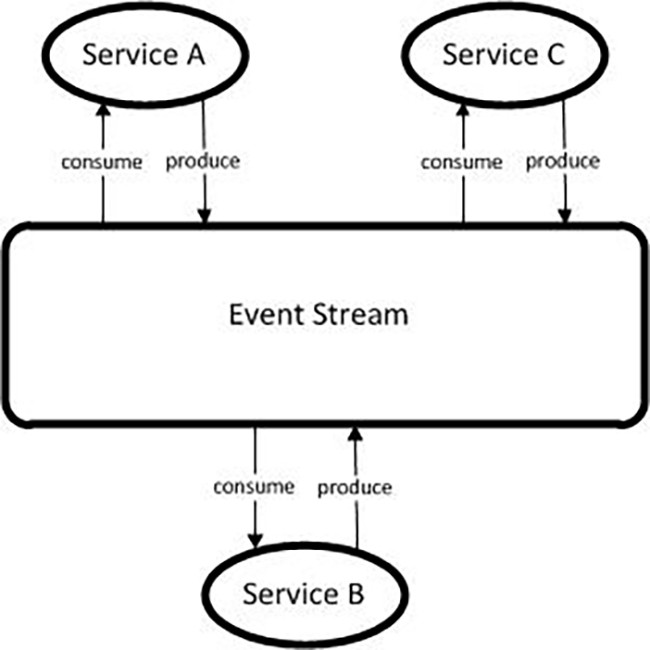
编排优势
>
启用更快的端到端处理,因为服务可以并行/异步执行。
更容易添加/更新服务,因为它们可以轻松插入/退出事件流。
与敏捷交付模型非常一致,因为团队可以专注于特定服务而不是整个应用程序。
控制是分布式的,因此不再有单个编排器作为故障的中心点。
有几种模式可以与反应式体系结构一起使用,以提供额外的好处。例如,事件源是指事件流存储所有事件并启用事件重播。这样,如果一个服务在事件仍在生成时宕机,当它重新联机时,它可以重播这些事件以进行备份。此外,还可以应用命令查询责任分离(CQRS)来分离读写活动。这使得每一个都可以独立地进行缩放。如果您的应用程序读得重,写得轻,或者读得重,写得轻,那么这就很方便了。
舞蹈设计权衡
>
异步编程通常是开发人员的重大思维转变。我倾向于认为它类似于递归,您无法通过查看它来弄清楚代码将如何执行,您必须考虑在特定时间点可能是真的所有可能性。
复杂性发生了变化。流控制现在被分解并分布在各个服务中,而不是集中在编排器中。每个服务都有自己的流逻辑,该逻辑将根据事件流中的特定数据确定其何时以及如何做出反应。
我会遵循常见的存储想法。
让每个微服务在公共存储中注册自己。让每个微服务注册它处理消息标识符的时间。
您可以计算出哪些n个服务应该处理它,以及n个服务中有多少个已经处理了它。
没有服务需要相互了解。
